
Archive for the 'Data Center' Category
-
September 25, 2024



Marvell COLORZ 800 Named Most Innovative Product at ECOC 2024
By Michael Kanellos, Head of Influencer Relations, Marvell
With AI computing and cloud data centers requiring unprecedented levels of performance and power, Marvell is leading the way with transformative optical interconnect solutions for accelerated infrastructure to meet the rising demand for network bandwidth.
At the ECOC 2024 Exhibition Industry Awards event, Marvell received the Most Innovative Pluggable Transceiver/Co-Packaged Module Award for the マーベル® COLORZ® 800 family. Launched in 2020 for ECOC’s 25th anniversary, the ECOC Exhibition Industry Awards spotlight innovation in optical communications, transport, and photonic technologies. This recognition highlights the company’s innovations in ZR/ZR+ technology for accelerated infrastructure and demonstrates its critical role in driving cloud and AI workloads.

-
September 22, 2024
Five Things to Know About the Future of Long Distance Optics
By Michael Kanellos, Head of Influencer Relations, Marvell
Coherent optical digital signal processors (DSPs) are the long-haul truckers of the communications world. The chips are essential ingredients in the 600+ subsea Internet cables that crisscross the oceans (see map here) and the extended geographic links weaving together telecommunications networks and clouds.
One of the most critical trends for long-distancer communications has been the shift from large, rack-scale transport equipment boxes running on embedded DSPs often from the same vendor to pluggable modules based on standardized form factors running DSPs from silicon suppliers tuned to the power limits of modules.
With the advent of 800G ZR/ZR+ modules, the market arrives at another turning point. Here’s what you need to know.
It’s the Magic of Modularity
PCs, smartphones, solar panels and other technologies that experienced rapid adoption had one thing in common: general agreement on the key ingredients. By building products around select components, accepted standards and modular form factors, an ecosystem of suppliers sprouted. And for customers that meant fewer shortages, lower prices and accelerated innovation.
The same holds true of pluggable coherent modules. 100 Gbps coherent modules based on the ZR specification debuted in 2017. The modules could deliver data approximately 80 kilometers and consumed approximately 4.5 watts per 100G of data delivered. Microsoft became an early adopter and used the modules to build a mesh of metro data centers1.

Flash forward to 2020. Power per 100G dropped to 4W and distance exploded: 120k connections became possible with modules based on the ZR standard and 400k with the ZR+ standard. (An organization called OIF maintains the ZR standard. ZR+ is controlled by OpenROADM. Module makers often make both varieties. The main difference between the two is the amplifier: the DSPs, number of channels and form factors are the same.) ®
The market responded. 400ZR/ZR+ became adopted more rapidly than any other technology in optical history, according to Cignal AI principal analyst Scott Wilkinson.
“It opened the floodgates to what you could do with coherent technology if you put it in the right form factor,” he said during a recent webinar.
-
June 18, 2024
Custom Compute in the AI Era
This article is the final installment in a series of talks delivered Accelerated Infrastructure for the AI Era, a one-day symposium held by Marvell in April 2024.
AI demands are pushing the limits of semiconductor technology, and hyperscale operators are at the forefront of adoption—they develop and deploy leading-edge technology that increases compute capacity. These large operators seek to optimize performance while simultaneously lowering total cost of ownership (TCO). With billions of dollars on the line, many have turned to custom silicon to meet their TCO and compute performance objectives.
But building a custom compute solution is no small matter. Doing so requires a large IP portfolio, significant R&D scale and decades of experience to create the mix of ingredients that make up custom AI silicon. Today, Marvell is partnering with hyperscale operators to deliver custom compute silicon that’s enabling their AI growth trajectories.Why are hyperscale operators turning to custom compute?
Hyperscale operators have always been focused on maximizing both performance and efficiency, but new demands from AI applications have amplified the pressure. According to Raghib Hussain, president of products and technologies at Marvell, “Every hyperscaler is focused on optimizing every aspect of their platform because the order of magnitude of impact is much, much higher than before. They are not only achieving the highest performance, but also saving billions of dollars.”
With multiple business models in the cloud, including internal apps, infrastructure-as-a-service (IaaS), and software-as-a-service (SaaS)—the latter of which is the fastest-growing market thanks to generative AI—hyperscale operators are constantly seeking ways to improve their total cost of ownership. Custom compute allows them to do just that. Operators are first adopting custom compute platforms for their mass-scale internal applications, such as search and their own SaaS applications. Next up for greater custom adoption will be third-party SaaS and IaaS, where the operator offers their own custom compute as an alternative to merchant options.
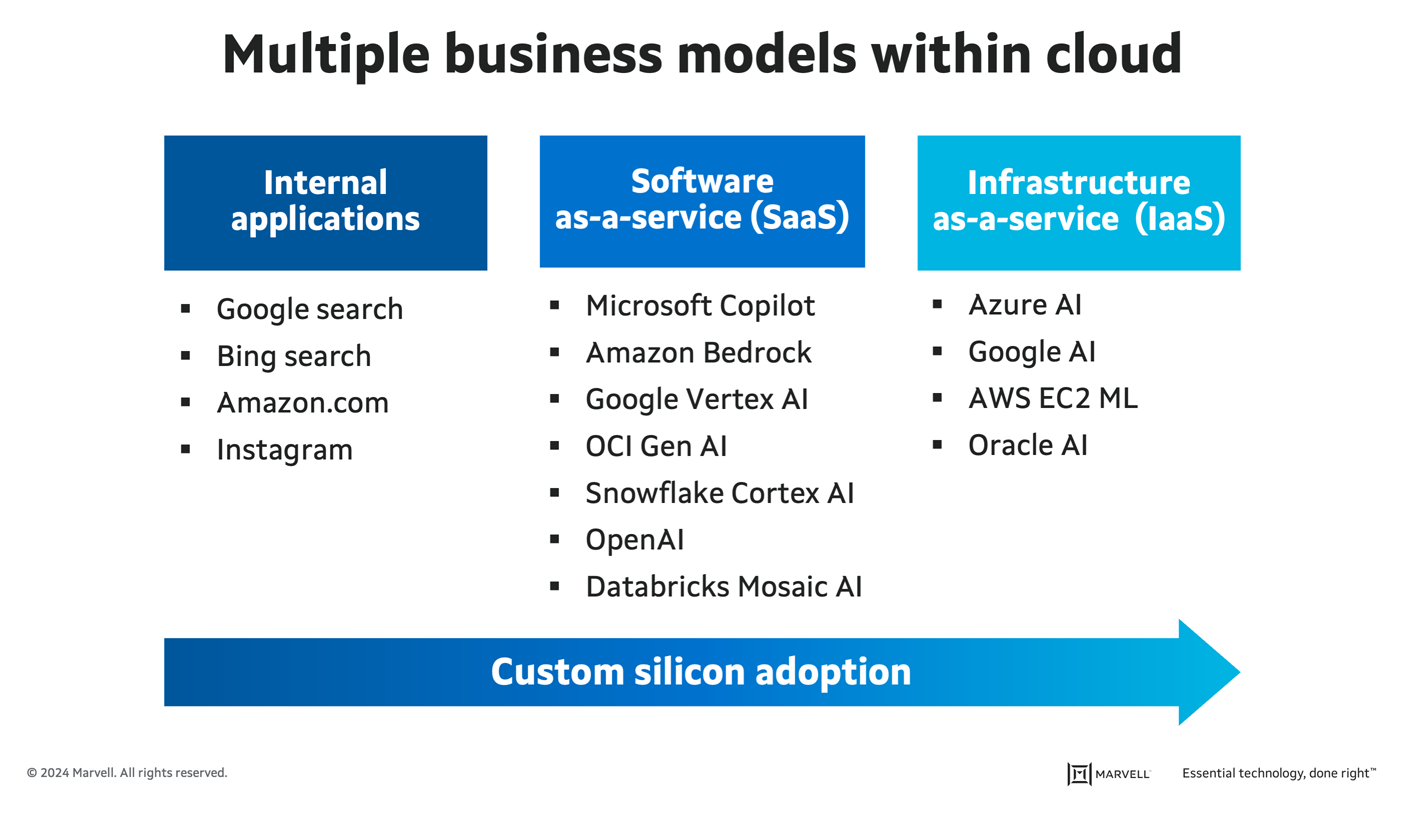
Progression of custom silicon adoption in hyperscale data centers.
-
June 11, 2024
How AI Will Drive Cloud Switch Innovation
This article is part five in a series on talks delivered at Accelerated Infrastructure for the AI Era, a one-day symposium held by Marvell in April 2024.
AI has fundamentally changed the network switching landscape. AI requirements are driving foundational shifts in the industry roadmap, expanding the use cases for cloud switching semiconductors and creating opportunities to redefine the terrain.
Here’s how AI will drive cloud switching innovation.
A changing network requires a change in scale
In a modern cloud data center, the compute servers are connected to themselves and the internet through a network of high-bandwidth switches. The approach is like that of the internet itself, allowing operators to build a network of any size while mixing and matching products from various vendors to create a network architecture specific to their needs.
Such a high-bandwidth switching network is critical for AI applications, and a higher-performing network can lead to a more profitable deployment.
However, expanding and extending the general-purpose cloud network to AI isn’t quite as simple as just adding more building blocks. In the world of general-purpose computing, a single workload or more can fit on a single server CPU. In contrast, AI’s large datasets don’t fit on a single processor, whether it’s a CPU, GPU or other accelerated compute device (XPU), making it necessary to distribute the workload across multiple processors. These accelerated processors must function as a single computing element.
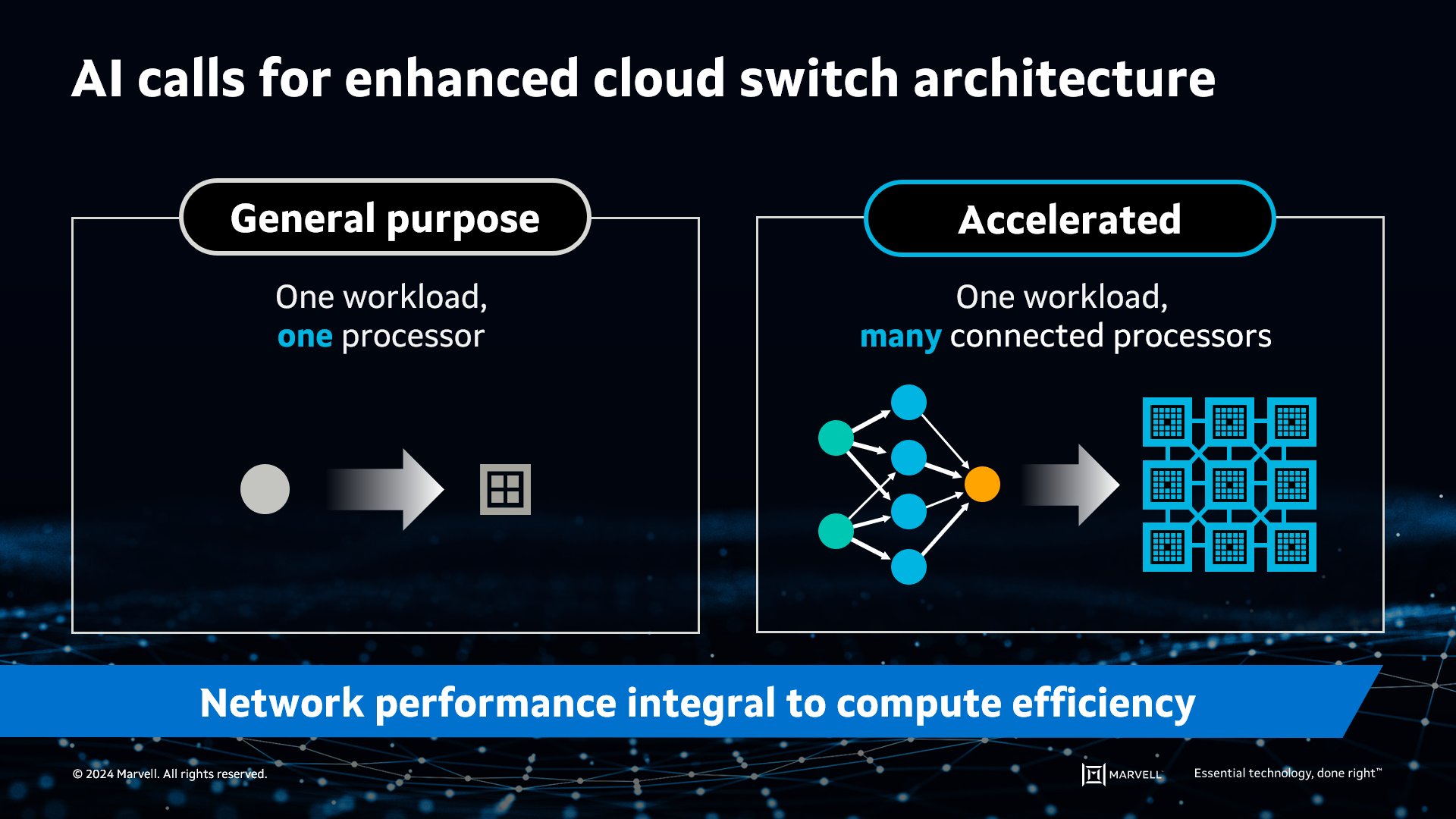
AI requires accelerated infrastructure to split workloads across many processors.
-
November 05, 2023
ファイバーチャネル: ミッションクリティカルな共有ストレージ接続のNo.1の選択
By Todd Owens, Director, Field Marketing, Marvell
Here at Marvell, we talk frequently to our customers and end users about I/O technology and connectivity. This includes presentations on I/O connectivity at various industry events and delivering training to our OEMs and their channel partners. Often, when discussing the latest innovations in Fibre Channel, audience questions will center around how relevant Fibre Channel (FC) technology is in today’s enterprise data center. This is understandable as there are many in the industry who have been proclaiming the demise of Fibre Channel for several years. However, these claims are often very misguided due to a lack of understanding about the key attributes of FC technology that continue to make it the gold standard for use in mission-critical application environments.
From inception several decades ago, and still today, FC technology is designed to do one thing, and one thing only: provide secure, high-performance, and high-reliability server-to-storage connectivity. While the Fibre Channel industry is made up of a select few vendors, the industry has continued to invest and innovate around how FC products are designed and deployed. This isn’t just limited to doubling bandwidth every couple of years but also includes innovations that improve reliability, manageability, and security.
