
This article is the final installment in a series of talks delivered Accelerated Infrastructure for the AI Era, a one-day symposium held by Marvell in April 2024.
AI demands are pushing the limits of semiconductor technology, and hyperscale operators are at the forefront of adoption—they develop and deploy leading-edge technology that increases compute capacity. These large operators seek to optimize performance while simultaneously lowering total cost of ownership (TCO). With billions of dollars on the line, many have turned to custom silicon to meet their TCO and compute performance objectives.
But building a custom compute solution is no small matter. Doing so requires a large IP portfolio, significant R&D scale and decades of experience to create the mix of ingredients that make up custom AI silicon. Today, Marvell is partnering with hyperscale operators to deliver custom compute silicon that’s enabling their AI growth trajectories.
Why are hyperscale operators turning to custom compute?
Hyperscale operators have always been focused on maximizing both performance and efficiency, but new demands from AI applications have amplified the pressure. According to Raghib Hussain, president of products and technologies at Marvell, “Every hyperscaler is focused on optimizing every aspect of their platform because the order of magnitude of impact is much, much higher than before. They are not only achieving the highest performance, but also saving billions of dollars.”
With multiple business models in the cloud, including internal apps, infrastructure-as-a-service (IaaS), and software-as-a-service (SaaS)—the latter of which is the fastest-growing market thanks to generative AI—hyperscale operators are constantly seeking ways to improve their total cost of ownership. Custom compute allows them to do just that. Operators are first adopting custom compute platforms for their mass-scale internal applications, such as search and their own SaaS applications. Next up for greater custom adoption will be third-party SaaS and IaaS, where the operator offers their own custom compute as an alternative to merchant options.
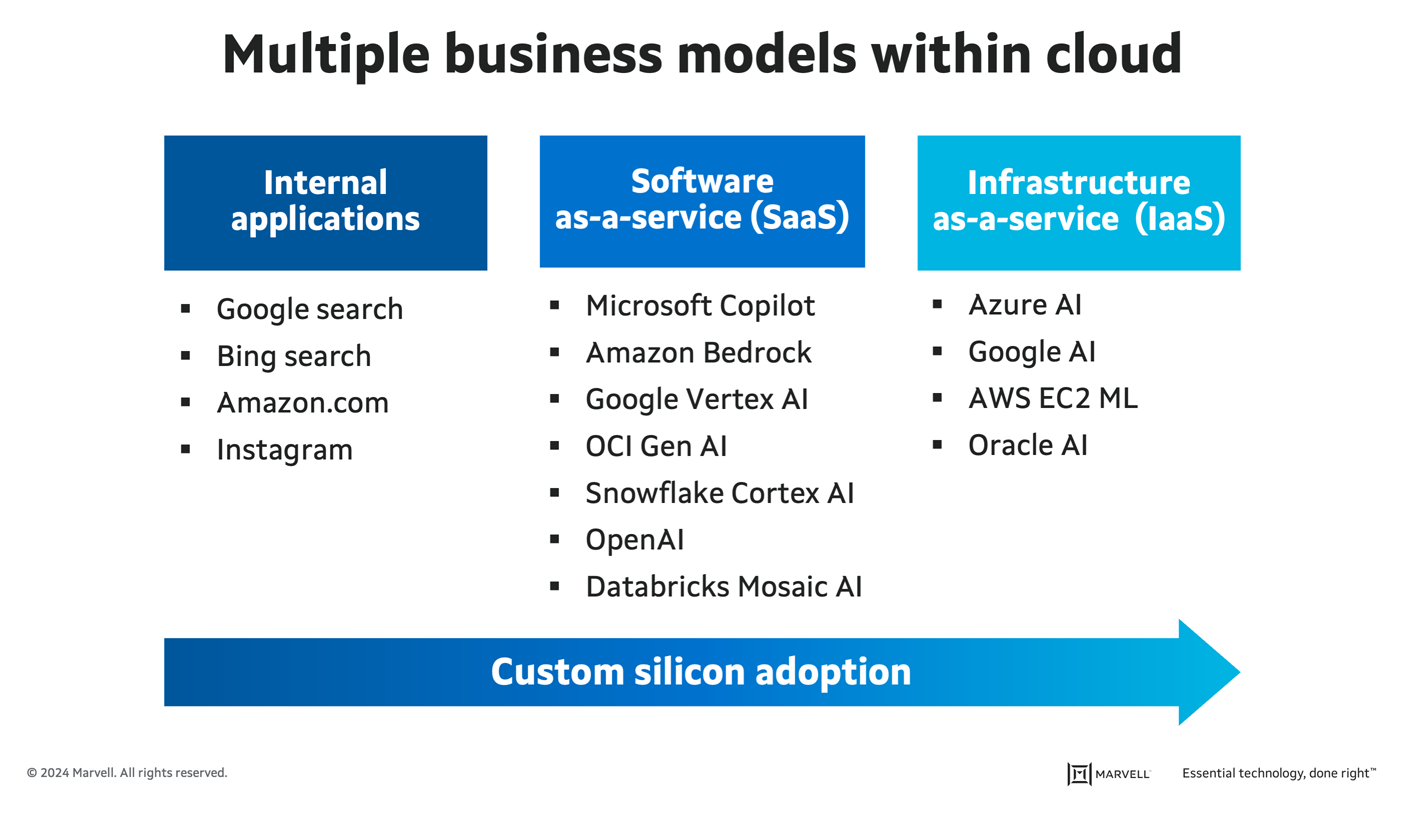
Progression of custom silicon adoption in hyperscale data centers.
What makes custom compute so complex?
In 1990, a typical processor chip had about one million transistors, and design verification was required for just gate-level functionality and timing. Today, the most advanced custom AI chips have about 100 billion transistors arrayed in a complex, multi-chip system with reticle-sized dies1. Verifying designs for these “systems-in-package” encompasses the entire range of system-on-chip testing, as well as cross-die timing, multi-chip power, connectivity, thermal, chiplet-to-chiplet signal integrity, and mechanical stress. Creating a full custom compute silicon solution with this level of complexity requires the right process node, critical intellectual property (IP), and advanced packaging technologies, all of which must be proven before hyperscale operators will adopt it.
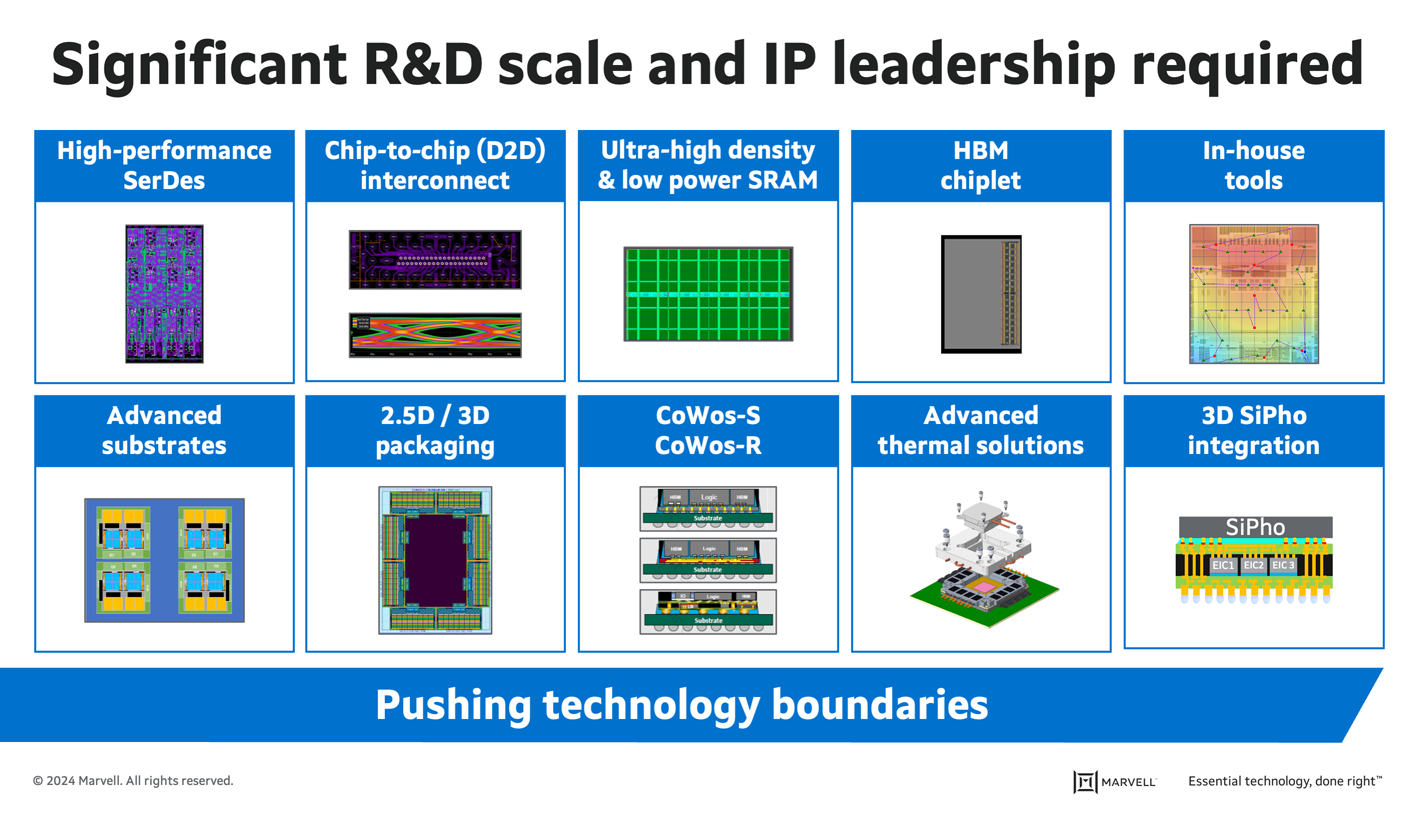
Custom compute development requires IP breadth and R&D scale.
In the world of custom compute, the boundaries of technology are constantly being pushed. By the time a hyperscale operator installs the latest technology iteration, they’re already looking for the next one. Their data center architecture depends on the availability of IPs, and those IPs require unique expertise and a sizeable investment—a foundational investment Marvell has been making in alignment with its accelerated infrastructure strategy.
Anatomy of custom compute CPUs and AI accelerators
Designing, delivering, and deploying a custom compute CPU starts with the core CPU but goes much further. While all core chips must be optimized for power, performance, and cost, the performance of each chip relies heavily on how well they are connected. High-bandwidth die-to-die interconnect technologies are crucial for creating a cohesive, multi-die solution that functions as a single compute entity, including high-bandwidth memory and I/O. Delivering and deploying such a custom compute CPU also requires ensuring production, volume, and yield can keep pace with demand.
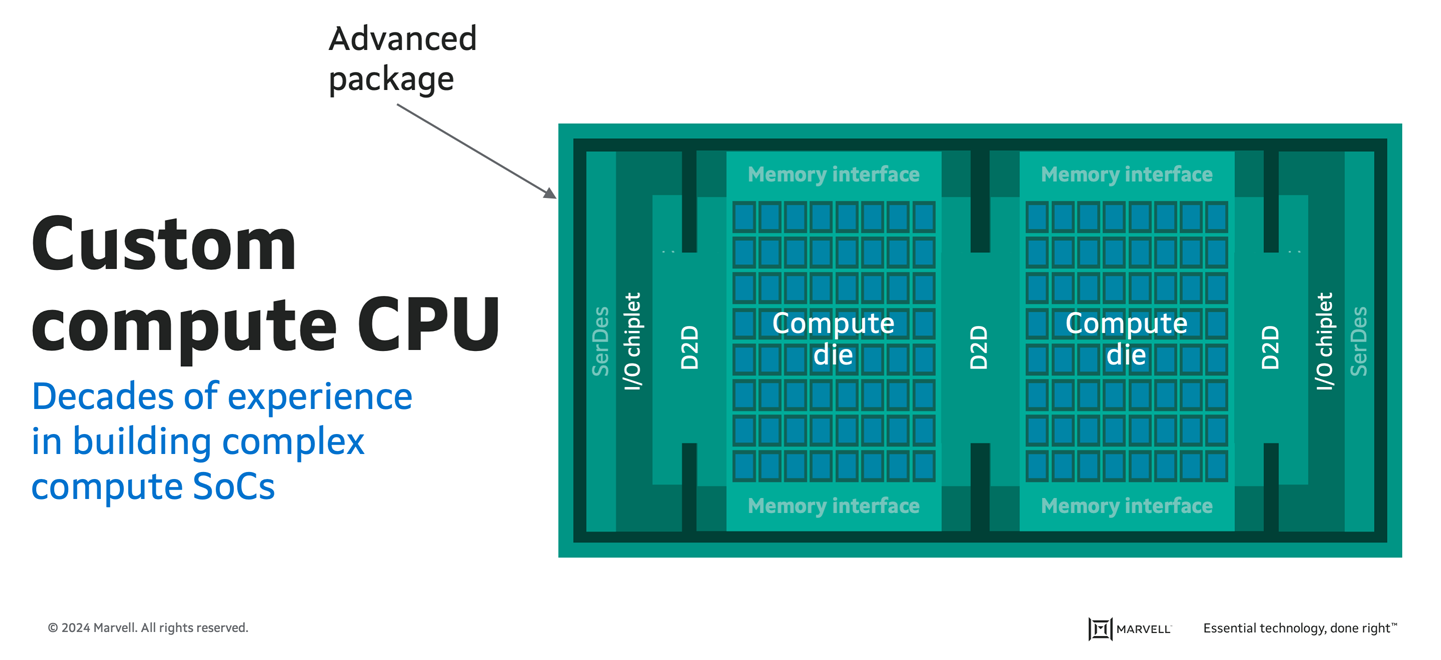
Custom compute CPUs must function as single entities. Marvell IP is shown in green.
High-end custom AI accelerator chips share a comparable complexity with custom compute CPUs. According to Raghib Hussain, "All the problems that you have to solve here [with AI accelerators] are similar to problems that our processor team has been solving for decades." The bandwidth and memory requirements are significantly greater for AI applications, but the entire package must still function as a single unit to deliver the necessary performance. Marvell has adopted a modular approach that separates the I/O and memory, allowing operators to upgrade chips if the memory technology improves, swap out a process node if changes are made, and more.
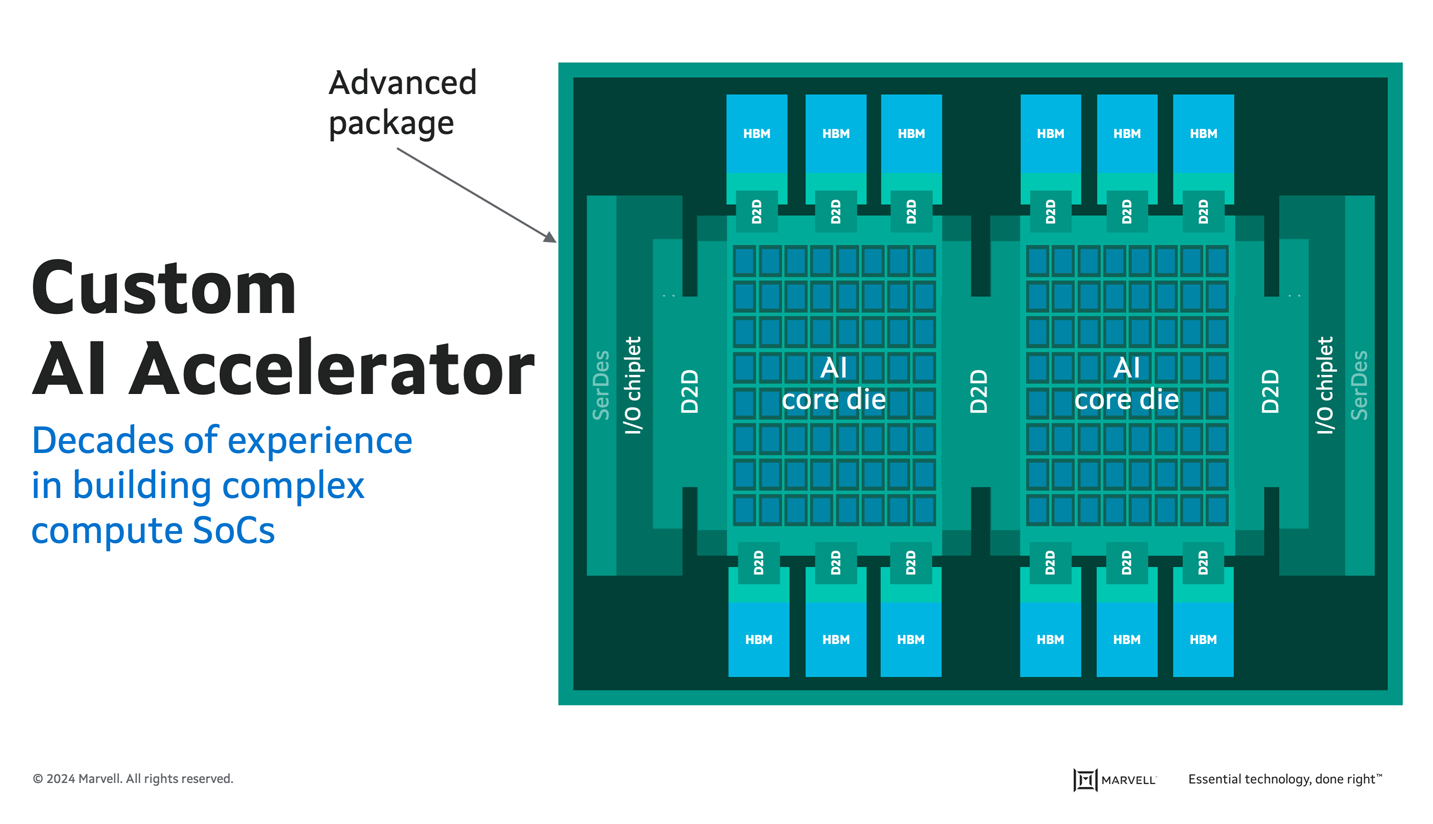
Like custom compute CPUs, custom AI accelerators must function as a single cohesive unit (Marvell IP shown in green).
Why hyperscale operators partner with Marvell
In today's market, hyperscale operators seek to invest in a semiconductor partner with the right IP portfolio and expertise to meet their current and future needs. Through organic development and strategic acquisitions, Marvell has, for decades, invested in and proven the efficacy of its leading-edge process designs, critical IP, and packaging technologies. Marvell offers all the capabilities necessary to deliver a custom compute platform that supports the demands of AI. With a portfolio of high-performance compute solutions and IP, Marvell meets the needs of hyperscale operators as they continue to build better, faster accelerated infrastructure.
1. Source: Our World in Data, Marvell estimates
# # #
This blog contains forward-looking statements within the meaning of the federal securities laws that involve risks and uncertainties. Forward-looking statements include, without limitation, any statement that may predict, forecast, indicate or imply future events, results or achievements. Actual events, results or achievements may differ materially from those contemplated in this blog. Forward-looking statements are only predictions and are subject to risks, uncertainties and assumptions that are difficult to predict, including those described in the “Risk Factors” section of our Annual Reports on Form 10-K, Quarterly Reports on Form 10-Q and other documents filed by us from time to time with the SEC. Forward-looking statements speak only as of the date they are made. Readers are cautioned not to put undue reliance on forward-looking statements, and no person assumes any obligation to update or revise any such forward-looking statements, whether as a result of new information, future events or otherwise.
Tags: AI, AI infrastructure, custom computing, AI accelerator processing units, Hyperscale data centers
