
As data growth continues at a tremendously rapid pace, data centers have a strong demand for scalable, flexible, and high bandwidth utilization of storage solutions. Data centers need an efficient infrastructure to meet the growing requirements of next-generation high performance computing (HPC), machine learning (ML)/artificial intelligence (AI), composable disaggregated infrastructure (CDI), and storage expansion shelf applications which necessitate scalable, high performance, and cost-efficient technologies. Hyperscalers and storage OEMs tend to scale system-level performance linearly, driven by the number of NVMe SSDs that plug into the system. However, current NVMe-oF storage target Just-A-Bunch-Of-Flash (JBOF) architecture connects fast performance NVMe SSDs behind the JBOF components, causing system-level performance bottlenecks due to CPU, DRAM, PCIe switch and smartNIC bandwidth. In addition, JBOF architecture requires a fixed ratio of CPU and SSDs which results in underutilized resources. Another challenge with JBOF architecture is the scalability of CPU, DRAM, and smartNIC devices does not match the total bandwidth of corresponding NVMe SSDs in the system due to the overall system cost overhead and thus, impacts system-level performance.
Marvell introduced its industry-first NVMe-oF to NVMe SSD converter controller, the 88SN2400, as a data center storage solution application. It enables the industry to introduce EBOF storage architecture which provides an innovative approach to address JBOF architecture challenges, and truly disaggregate storage from the compute. EBOF architecture replaces JBOF bottleneck components like CPUs, DRAM and smartNICs with Ethernet switch and terminates NVMe-oF either on the bridge or Ethernet SSD. Marvell is enabling NAND vendors to offer Ethernet SSD products. EBOF architecture allows scalability, flexibility, and full utilization of PCIe NVMe drives.
Los Alamos National Laboratory (LANL) and Marvell are collaborating to leverage NVMe SSD full performance characteristics in HPC storage workloads with EBOF. The LANL team is leading efforts to evaluate EBOF for HPC storage systems and workloads. HPC workloads require storage infrastructure that scales endlessly and delivers unmatched I/O levels, so it requires a strategic partnership for the successful deployment into HPC data centers. LANL conducted a series of performance benchmarks and functionality tests with the Marvell® 88SN2400 converter controller and Foxconn Irene EBOF. The Foxconn Irene EBOF consists of a dual switch module in a standard 19” 2U chassis to support high availability mission-critical applications; each module used a Marvell Prestera® switch that supports six 200GbE uplink ports (total of 12ports in a 2U enclosure) and up to 50GbE link to 24 NVMe SSDs.
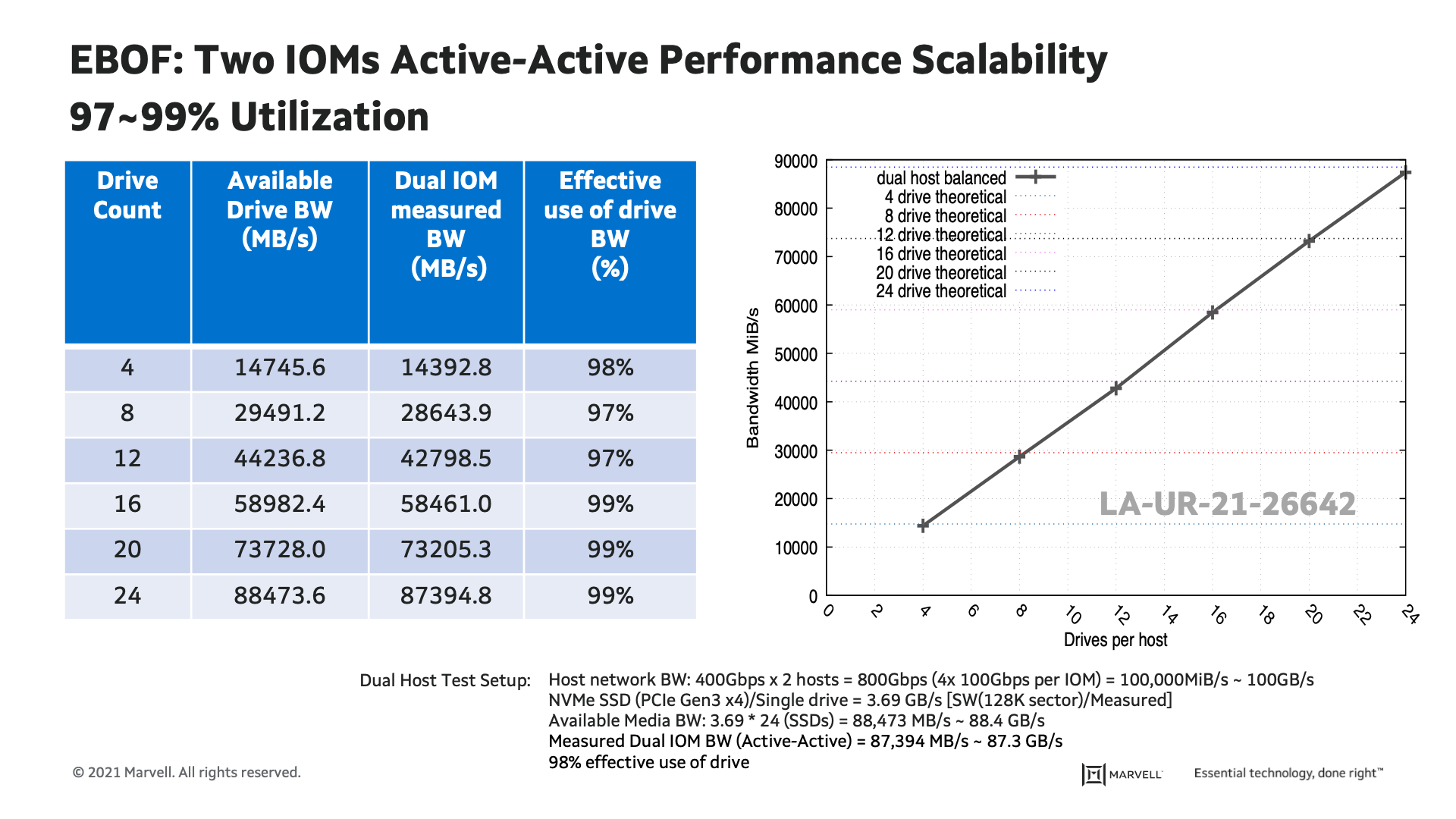
Block Devices Performance Benchmark in High Availability (HA) Configuration:
In the first phase, block devices performance in a high availability (HA) configuration was measured with fully populated NVMe SSDs in an EBOF using standard HPC storage benchmarking tools. The test set-up included: Two hosts servers; total of 800Gb/s connected to eight of the twelve ports of EBOF dual modules (400Gb/s per module) and 24 NVMe SSDs connected to the Marvell 88SN2400 converter controller. As shown in the plot, EBOF demonstrated 87.3GB/s Sequential Write (SW) in a 2U enclosure, and 98% bandwidth utilization of NVMe SSDs. EBOF delivered a high availability (HA) solution without the need of dual-ported SSDs as compared to JBOF. Also, data confirmed that 24 NVMe SSD performance scales linearly.

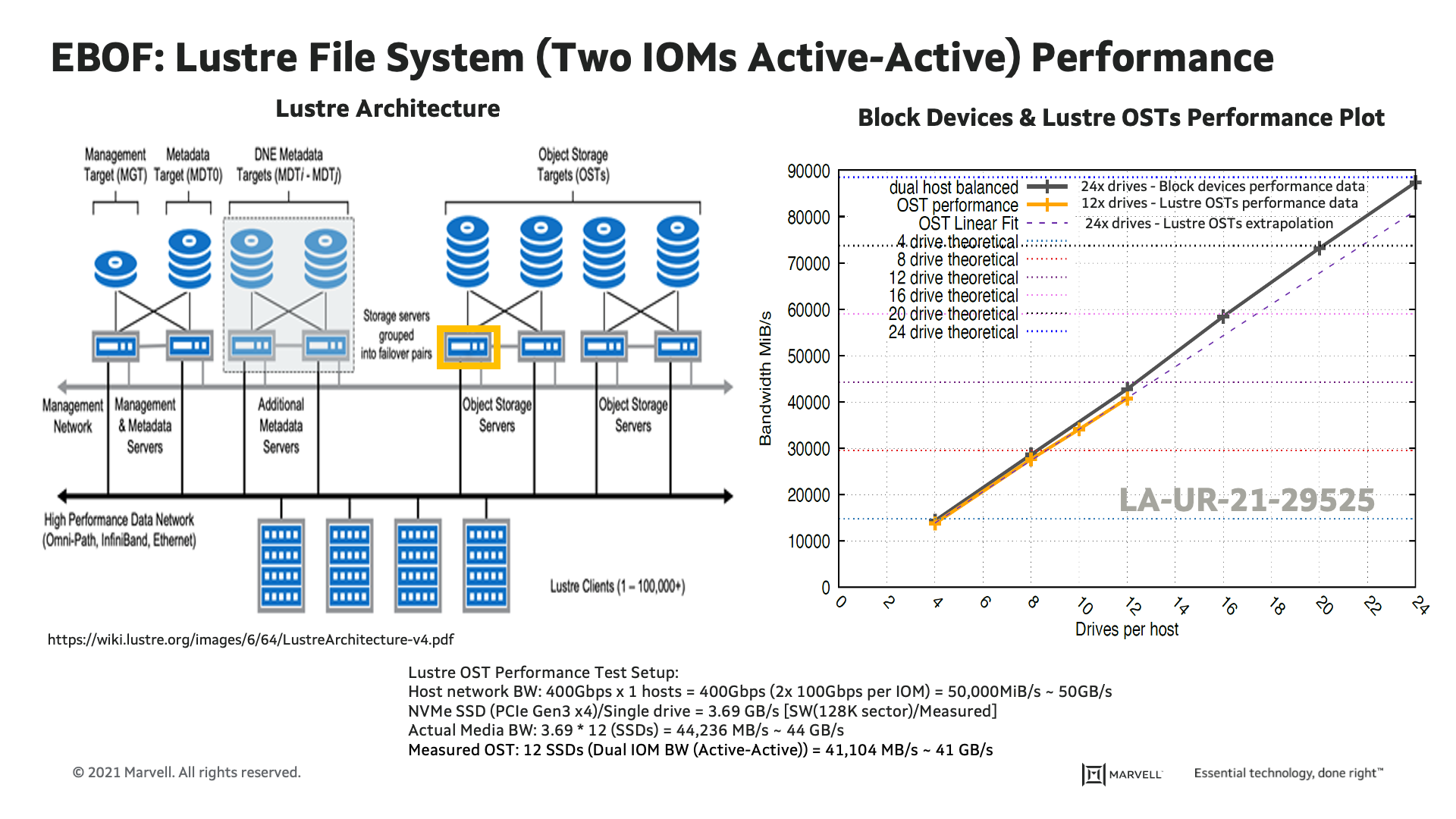
Lustre File System Performance Benchmark in High Availability (HA) Configuration:
In the second phase, EBOF performance data was collected using a Lustre file system. Lustre is an open source distributed parallel file system used by a large majority of the high-performance computing data centers to provide high bandwidth, parallel access to compute clusters. Lustre employs a client-server network architecture and is based on distributed object-based storage. Lustre’s architecture is such that the namespace is stored separately from file data. This requires separate services for supporting metadata and data requests. A Lustre file system is usually architected to be highly available in order to minimize downtime due to component failures.
Lustre file systems are traditionally deployed to provide a high bandwidth solution for workloads that require parallel access. NVMe SSDs are becoming a key building block in providing peak performance to these HPC workflows. Having NVMe SSDs available over the network presents a unique opportunity to move away from rigid storage systems and enables a more flexible design and deployment strategy for HPC storage systems. One example of this would be targeting the needs of a specific workload, IOPs for example, while still providing a stable and highly available resource to bandwidth needy users, such as a Lustre-based file system.
The test set-up included: One host server; total of 400Gb/s connected to four of the twelve ports of EBOF dual switch modules (200Gb/s per module) and 12 NVMe SSDs connected to the Marvell 88SN2400 converter controller. Performance benchmark was collected on Lustre OST. Measured 12 drives SW in a dual IOMs (active-active) recorded 41GB/s vs 44GB/s using block devices. OST extrapolation data of 24 NVMe SSD SW is 81GB/s versus 88GB/s for 24 block devices. These results confirm that Lustre OSTs performance numbers are highly competitive to block devices.

Summary
Marvell proudly collaborated with LANL on the high-availability (HA) and Lustre file system performance benchmark using Foxconn Irene EBOF. Results shows that 98% and 95% of bandwidth utilization of NVMe SSDs for high availability (HA) configuration and Lustre, respectively. EBOF enables scalability, flexibility, and better utilization of NVMe SSDs and exposes the full bandwidth of each NVMe SSD linearly on a system-level benchmark which is required for hyperscale data centers in a disaggregated deployment. Marvell and LANL continue to explore other real-world application use cases which take can advantage of EBOF like AI/ML, CDI, and HPC workloads and we look forward to reporting out on additional benchmark results as they are generated. Stay tuned!
For more information on the Foxconn Irene EBOF platform, please visit:
http://www.ingrasys.com/en/product/Ingrasys_EBOF_PR
Tags: EBOF Platform, Foxconn Irene EBOF, HPC Storage Workloads, Lustre File System Performance Benchmark, NVMe SSD converter controller, NVMe SSDs, NVMe-oF storage
