
A massive amount of data is being generated at the edge, data center and in the cloud, driving scale out Software-Defined Storage (SDS) which, in turn, is enabling the industry to modernize data centers for large scale deployments. Ceph is an open-source, distributed object storage and massively scalable SDS platform, contributed to by a wide range of major high-performance computing (HPC) and storage vendors. Ceph BlueStore back-end storage removes the Ceph cluster performance bottleneck, allowing users to store objects directly on raw block devices and bypass the file system layer, which is specifically critical in boosting the adoption of NVMe SSDs in the Ceph cluster. Ceph cluster with EBOF provides a scalable, high-performance and cost-optimized solution and is a perfect use case for many HPC applications. Traditional data storage technology leverages special-purpose compute, networking, and storage hardware to optimize performance and requires proprietary software for management and administration. As a result, IT organizations neither scale-out nor make it feasible to deploy petabyte or exabyte data storage from a CAPEX and OPEX perspective.
Ingrasys (subsidiary of Foxconn) is collaborating with Marvell to introduce an Ethernet Bunch of Flash (EBOF) storage solution which truly enables scale-out architecture for data center deployments. EBOF architecture disaggregates storage from compute and provides limitless scalability, better utilization of NVMe SSDs, and deploys single-ported NVMe SSDs in a high-availability configuration on an enclosure level with no single point of failure.
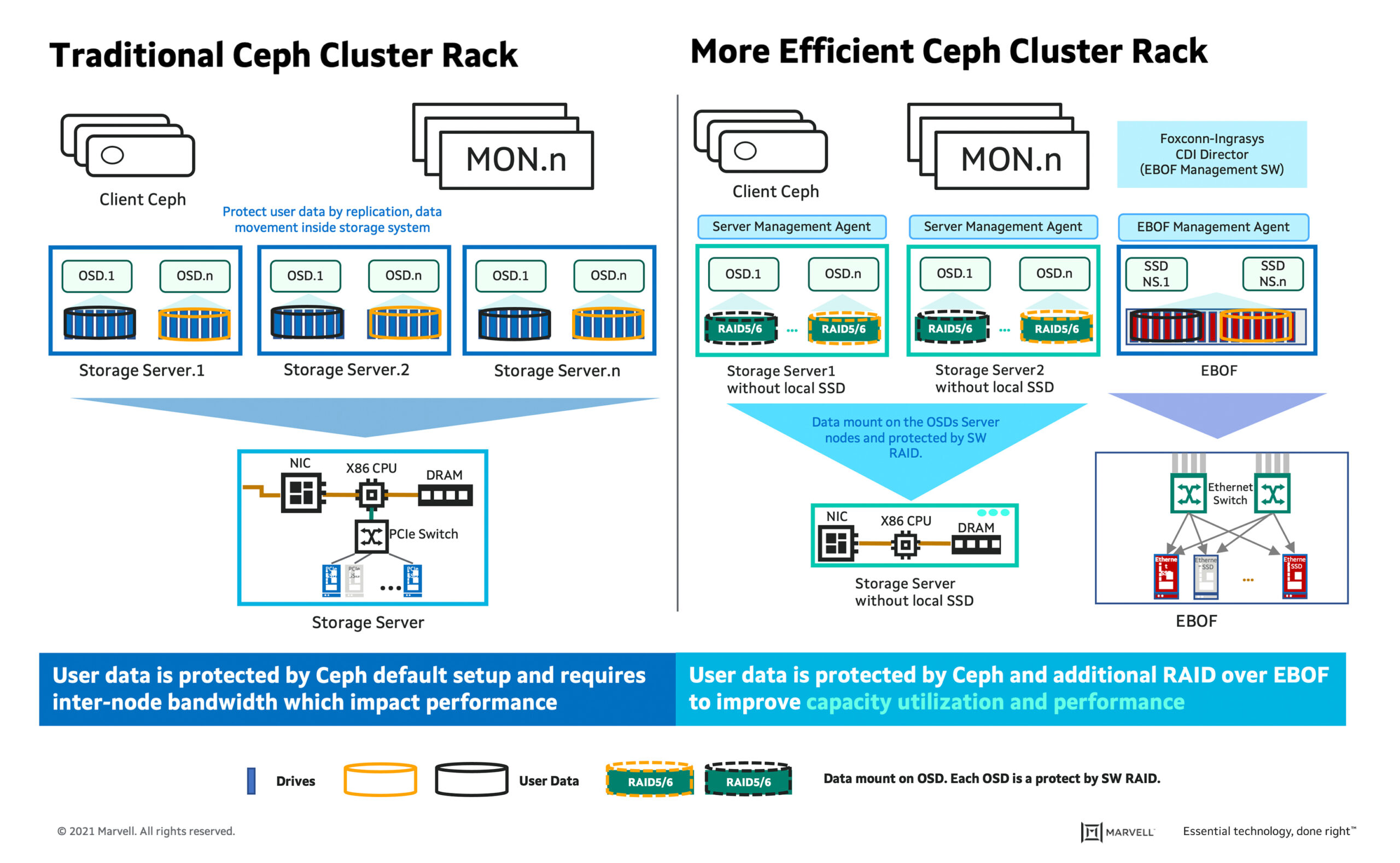
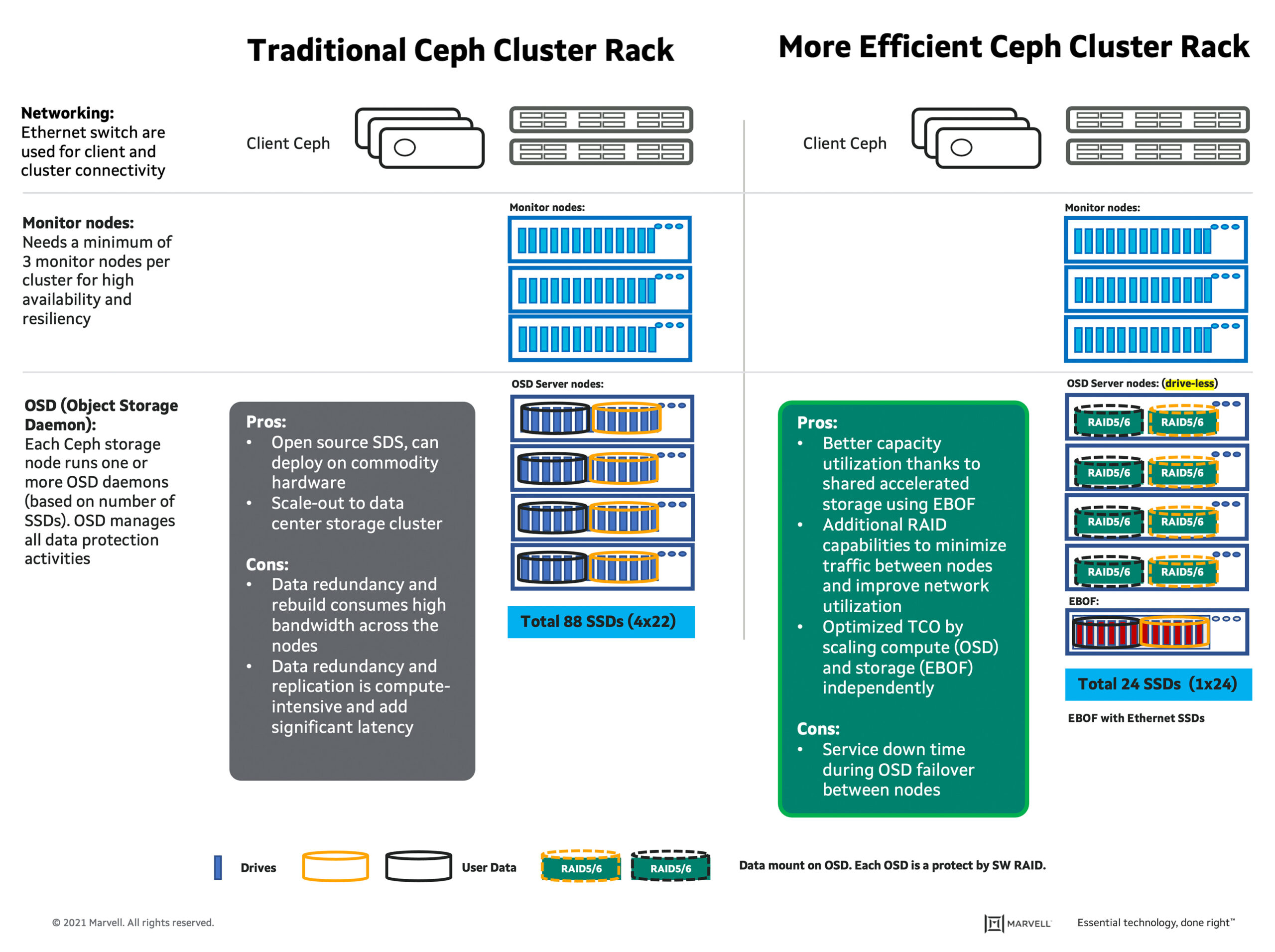
Ceph is deployed on commodity hardware and built on multi-petabyte storage clusters. It is highly flexible due to its distributed nature. EBOF use in a Ceph cluster enables added storage capacity to scale up and scale out at an optimized cost and facilitates high-bandwidth utilization of SSDs. A typical rack-level Ceph solution includes a networking switch for client, and cluster connectivity; a minimum of 3 monitor nodes per cluster for high availability and resiliency; and Object Storage Daemon (OSD) host for data storage, replication, and data recovery operations. Traditionally, Ceph recommends 3 replicas at a minimum to distribute copies of the data and assure that the copies are stored on different storage nodes for replication, but this results in lower usable capacity and consumes higher bandwidth. Another challenge is that data redundancy and replication are compute-intensive and add significant latency. To overcome all these challenges, Ingrasys has introduced a more efficient Ceph cluster rack developed with management software – Ingrasys Composable Disaggregate Infrastructure (CDI) Director.
The Ingrasys Composable Disaggregate Infrastructure (CDI) Director management software is at the core of the EBOF storage solution. The CDI Director is designed to eliminate management effort of disaggregated infrastructure. It effectively reduces deployment and maintenance cost, improves resource utilization, enhances efficiency, and hence delivers greater overall performance.
“The strategic advantage of the Ingrasys CDI solution is the combination of the flexibility and efficiency inherent in composable systems, with the raw performance delivered by the EBOF storage based on Ethernet switching and Marvell IP that terminates NVMe-over-Fabrics transactions at each SSD,” said Brad Reger, VP & Principal Architect, Ingrasys Technology. “The solutions we’ve built with Marvell can significantly reduce data center CAPEX and OPEX, with no compromise in performance.”
The CDI Director software can discover EBOF storage, collect server inventories, and automate the process of assembling storage volumes from shared EBOF pools. It also offers server failover policy setting to support high availability (HA) architecture. In addition to an intuitive user interface, the CDI Director offers API and reference drivers for the integration with off-the-shelf software like Kubernetes, OpenStack or Ceph.
Instead of 3 replicas copied on a storage node, Ingrasys’ more efficient Ceph cluster rack uses each EBOF drive as OSD on the storage node without any local SSDs attached on the storage node. Each OSD is a RAID device which consists of multiple NVMe-oF drives. User data is protected by RAID. It provides flexibility to allocate EBOF drives to the server running the OSD process which provides more efficiency to utilize storage resources.
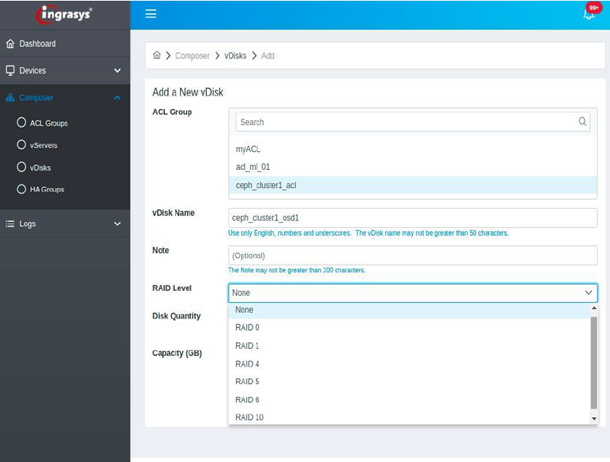
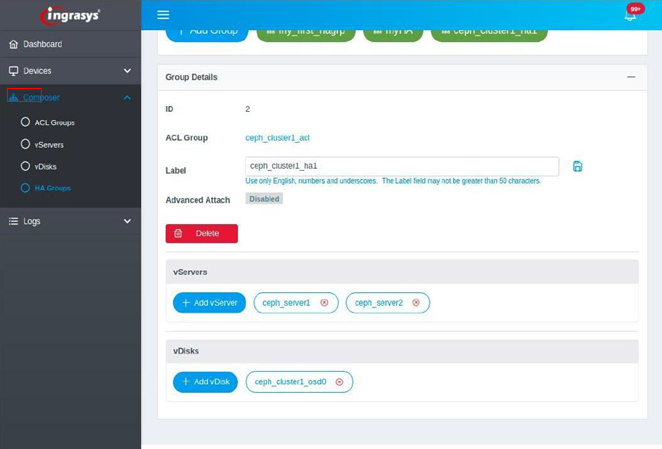
Ingrasys CDI Director provides an intuitive WebUI to configure EBOF drives for Ceph cluster. EBOF volumes consist of multiple NVMe-oF drives. Drives will be configured to the RAID device on the server node. It supports non-RAID and RAID0/1/4/5/6/10 configurations. It is recommended to configure OSD to RAID 5/6 to prevent an NVMe drive failure case. Storage servers and volumes can join to the HA Group. Every volume or server belongs to one high availability (HA) group; volumes can then migrate to one of the HA group servers if the connected server has crashed. Ceph OSD drives can be a failover between the Ceph OSD server within the HA Group. Ceph OSD will be connected to all servers in this HA group in advance. Each OSD process can only be activated in one server.
Ingrasys conducted a series of performance benchmarks with the Marvell® 88SN2400 converter controller and Kioxia EthernetSSD using the Ingrasys Irene EBOF. The Ingrasys Irene EBOF consists of a dual switch module in a standard 19” 2U chassis to support high-availability, mission-critical applications; each module uses a Marvell Prestera® switch that supports six 200GbE uplink ports (total of 12 ports in a 2U enclosure) and up to 50GbE link to 24 NVMe SSDs.
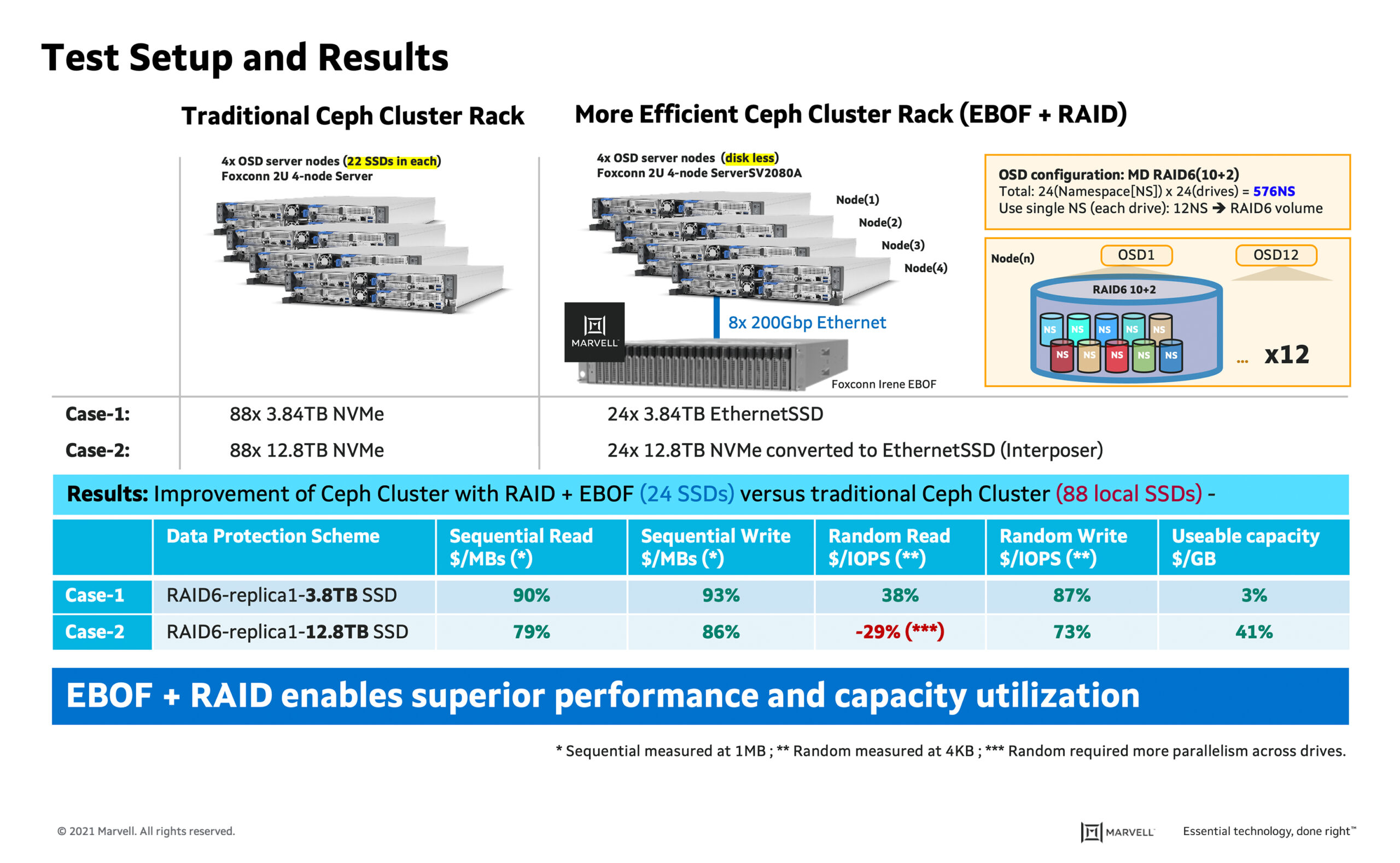
For the purposes of this blog, I have focused on a comparison of more efficient Ceph cluster rack vs traditional Ceph cluster. The more efficient Ceph cluster rack test set-up included: four OSD server nodes (Foxconn 2U 4-node ServerSV2080A) and no local SSDs attached on the server nodes. The OSD configuration included MD RAID6(10+2), 24 namespace per drive for a total of 576 namespaces and used 1 namespace from each drive to build RAID6 volume. OSDs manage a Linux RAID group of namespaces, instead of managing 3 replicas. RAID groups contain one namespace from each physical drive, so a physical drive failure can be covered by RAID for all OSDs in the storage servers. Ceph HA is used to monitor server nodes and failover to a new node if the current server node fails.
In the first phase, 24 Kioxia 3.84TB EthernetSSD were used for RAID6 replica-1 configuration. Case 1 shows 3% higher useable capacity with Random Write ($/IOPS) and Random Read ($/IOPS) improvements at 87% and 38%, respectively. In the second phase, 24 12.8TB NVMe drives were used with the active interposer for RAID6 replica-1 configuration.Case 2 shows 41% higher useable capacity with 73% improvement on Random Write ($/IOPS) by increasing the capacity of each drive to 12.8TB, but it impacts the Random Read ($/IOPS) measurement. This is because Random Read execution required more parallelism across drives and the more efficient Ceph cluster used only 24 drives as compared to 88 drives in the traditional Ceph Cluster. The data demonstrates the tradeoff between useable capacity and Random Read ($/IOPS) performance.
The traditional Ceph cluster four OSD server node incorporated 88 (total) local SSDs on four servers.The results clearly indicate that the Ceph cluster with EBOF is significantly cost optimized compared to the traditional Ceph cluster. Ingrasys is running latency benchmarks for comparison. Please stay tuned for more data. Marvell is proud to have collaborated with Ingrasys on this Ceph cluster exercise and demonstrate the value of the Ethernet Bunch of Flash (EBOF) solution in contributing to lower total cost of ownership in the data center.
Summary:
For more information on the Ingrasys Irene EBOF platform, please visit https://www.ingrasys.com/es2000
Tags: Ceph cluster, data storage, EBOF architecture, EBOF storage solution, HPC, HPC applications, NVMe SSDs, SDS, SDS platform
