- PRODUCTS
- COMPANY
- SUPPORT
- PRODUCTS
- BY TYPE
- BY MARKET
Compute
Networking
- Automotive
- Coherent DSP
- Data Center Switches
- DCI Optical Modules
- Enterprise Switches
- Ethernet Controllers
- Ethernet PHYs
- Linear Driver
- PAM DSP
- PCIe Retimers
- Transimpedance Amplifiers
Storage
Custom
- COMPANY
Our Company
Media
Contact
- SUPPORT
BY TYPE
Compute
Networking
Custom
BY MARKET

Posts Tagged 'custom computing'
-
June 18, 2024



Custom Compute in the AI Era
This article is the final installment in a series of talks delivered Accelerated Infrastructure for the AI Era, a one-day symposium held by Marvell in April 2024.
AI demands are pushing the limits of semiconductor technology, and hyperscale operators are at the forefront of adoption—they develop and deploy leading-edge technology that increases compute capacity. These large operators seek to optimize performance while simultaneously lowering total cost of ownership (TCO). With billions of dollars on the line, many have turned to custom silicon to meet their TCO and compute performance objectives.
But building a custom compute solution is no small matter. Doing so requires a large IP portfolio, significant R&D scale and decades of experience to create the mix of ingredients that make up custom AI silicon. Today, Marvell is partnering with hyperscale operators to deliver custom compute silicon that’s enabling their AI growth trajectories.Why are hyperscale operators turning to custom compute?
Hyperscale operators have always been focused on maximizing both performance and efficiency, but new demands from AI applications have amplified the pressure. According to Raghib Hussain, president of products and technologies at Marvell, “Every hyperscaler is focused on optimizing every aspect of their platform because the order of magnitude of impact is much, much higher than before. They are not only achieving the highest performance, but also saving billions of dollars.”
With multiple business models in the cloud, including internal apps, infrastructure-as-a-service (IaaS), and software-as-a-service (SaaS)—the latter of which is the fastest-growing market thanks to generative AI—hyperscale operators are constantly seeking ways to improve their total cost of ownership. Custom compute allows them to do just that. Operators are first adopting custom compute platforms for their mass-scale internal applications, such as search and their own SaaS applications. Next up for greater custom adoption will be third-party SaaS and IaaS, where the operator offers their own custom compute as an alternative to merchant options.
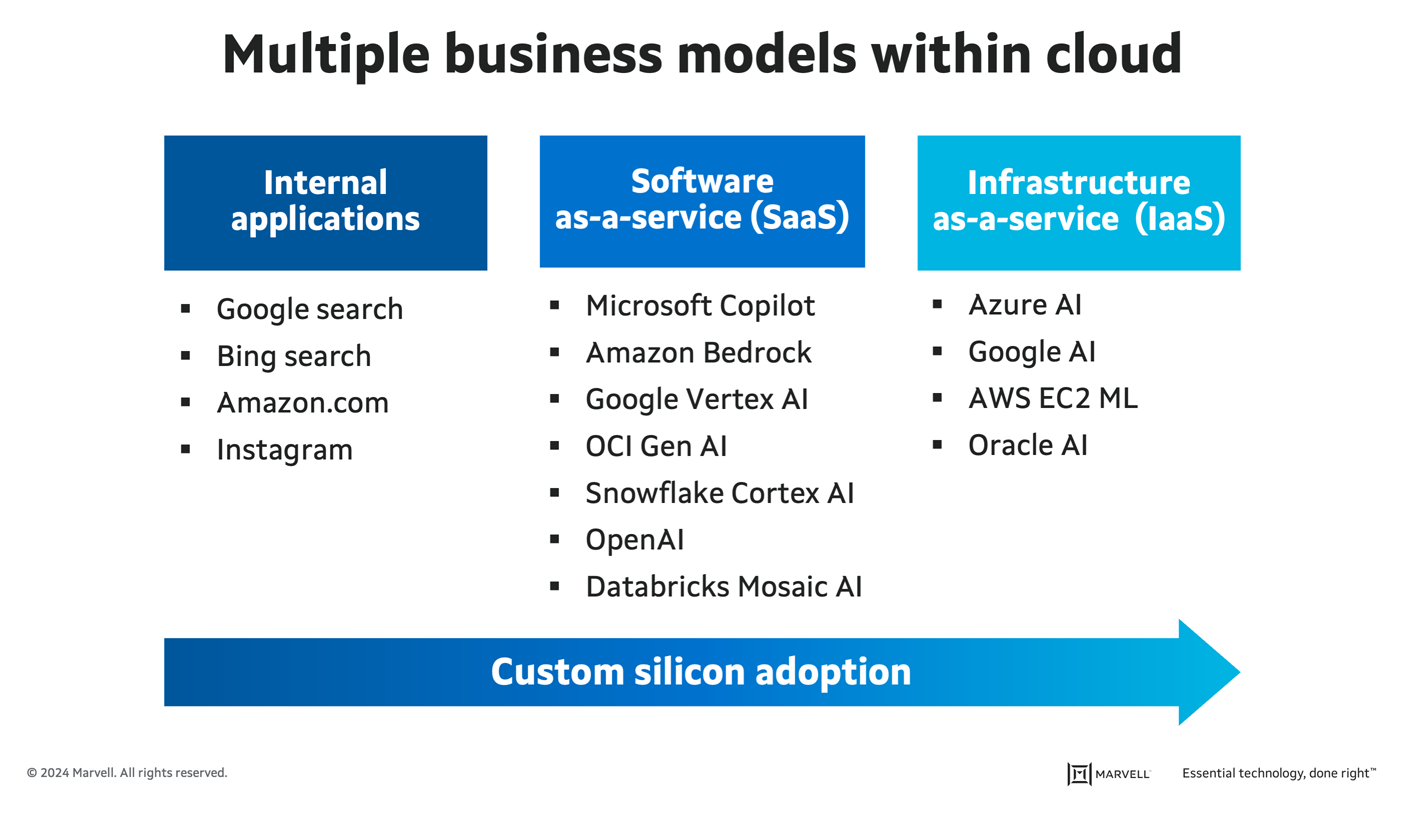
Progression of custom silicon adoption in hyperscale data centers.
-
May 14, 2024
The AI Opportunity at Marvell
Two trillion dollars. That’s the GDP of Italy. It’s the rough market capitalization of Amazon, of Alphabet and of Nvidia. And, according to analyst firm Dell’Oro, it’s the amount of AI infrastructure CAPEX expected to be invested by data center operators over the next five years. It’s an historically massive investment, which begs the question: Does the return on AI justify the cost?
The answer is a resounding yes.
AI is fundamentally changing the way we live and work. Beyond chatbots, search results, and process automation, companies are using AI to manage risk, engage customers, and speed time to market. New use cases are continuously emerging in manufacturing, healthcare, engineering, financial services, and more. We’re at the beginning of a generational inflection point that, according to McKinsey, has the potential to generate $4.4 trillion in annual economic value.
In that light, two trillion dollars makes sense. It will be financed through massive gains in productivity and efficiency.
Our view at Marvell is that the AI opportunity before us is on par with that of the internet, the PC, and cloud computing. “We’re as well positioned as any company in technology to take advantage of this,” said chairman and CEO Matt Murphy at the recent Marvell Accelerated Infrastructure for the AI Era investor event in April 2024.
-
June 12, 2023
AI and the Tectonic Shift Coming to Data Infrastructure
By Michael Kanellos, Head of Influencer Relations, Marvell
AI’s growth is unprecedented from any angle you look at it. The size of large training models is growing 10x per year. ChatGPT’s 173 million plus users are turning to the website an estimated 60 million times a day (compared to zero the year before.). And daily, people are coming up with new applications and use cases.
As a result, cloud service providers and others will have to transform their infrastructures in similarly dramatic ways to keep up, says Chris Koopmans, Chief Operations Officer at Marvell in conversation with Futurum’s Daniel Newman during the Six Five Summit on June 8, 2023.
“We are at the beginning of at least a decade-long trend and a tectonic shift in how data centers are architected and how data centers are built,” he said.
The transformation is already underway. AI training, and a growing percentage of cloud-based inference, has already shifted from running on two-socket servers based around general processors to systems containing eight more GPUs or TPUs optimized to solve a smaller set of problems more quickly and efficiently.
Recent Posts
Archives
Categories
- 5G (12)
- AI (21)
- Automotive (26)
- Cloud (9)
- Coherent DSP (5)
- Company News (101)
- Custom Silicon Solutions (2)
- Data Center (44)
- Data Processing Units (22)
- Enterprise (25)
- ESG (6)
- Ethernet Adapters and Controllers (12)
- Ethernet PHYs (4)
- Ethernet Switching (36)
- Fibre Channel (10)
- Marvell Government Solutions (2)
- Networking (33)
- Optical Modules (12)
- Security (6)
- Server Connectivity (23)
- SSD Controllers (6)
- Storage (22)
- Storage Accelerators (2)
- What Makes Marvell (32)

Copyright © 2024 Marvell, All rights reserved.
- Terms of Use
- Privacy Policy
- Contact