
Archive for the 'Data Center' Category
-
November 05, 2023



ファイバーチャネル: ミッションクリティカルな共有ストレージ接続のNo.1の選択
By Todd Owens, Director, Field Marketing, Marvell
Here at Marvell, we talk frequently to our customers and end users about I/O technology and connectivity. This includes presentations on I/O connectivity at various industry events and delivering training to our OEMs and their channel partners. Often, when discussing the latest innovations in Fibre Channel, audience questions will center around how relevant Fibre Channel (FC) technology is in today’s enterprise data center. This is understandable as there are many in the industry who have been proclaiming the demise of Fibre Channel for several years. However, these claims are often very misguided due to a lack of understanding about the key attributes of FC technology that continue to make it the gold standard for use in mission-critical application environments.
From inception several decades ago, and still today, FC technology is designed to do one thing, and one thing only: provide secure, high-performance, and high-reliability server-to-storage connectivity. While the Fibre Channel industry is made up of a select few vendors, the industry has continued to invest and innovate around how FC products are designed and deployed. This isn’t just limited to doubling bandwidth every couple of years but also includes innovations that improve reliability, manageability, and security.
-
October 19, 2023
AI時代のマーベルの光学技術とイノベーションに光を当てる
By Kristin Hehir, Senior Manager, PR and Marketing, Marvell
The sheer volume of data traffic moving across networks daily is mind-boggling almost any way you look at it. During the past decade, global internet traffic grew by approximately 20x, according to the International Energy Agency. One contributing factor to this growth is the popularity of mobile devices and applications: Smartphone users spend an average of 5 hours a day, or nearly 1/3 of their time awake, on their devices, up from three hours just a few years ago. The result is incredible amounts of data in the cloud that need to be processed and moved. Around 70% of data traffic is east-west traffic, or the data traffic inside data centers. Generative AI, and the exponential growth in the size of data sets needed to feed AI, will invariably continue to push the curb upward.
Yet, for more than a decade, total power consumption has stayed relatively flat thanks to innovations in storage, processing, networking and optical technology for data infrastructure. The debut of PAM4 digital signal processors (DSPs) for accelerating traffic inside data centers and coherent DSPs for pluggable modules have played a large, but often quiet, role in paving the way for growth while reducing cost and power per bit.
Marvell at ECOC 2023
At Marvell, we’ve been gratified to see these technologies get more attention. At the recent European Conference on Optical Communication, Dr. Loi Nguyen, EVP and GM of Optical at Marvell, talked with Lightwave editor in chief, Sean Buckley, on how Marvell 800 Gbps and 1.6 Tbps technologies will enable AI to scale.
-
October 18, 2023
データセンターの極端な模様替え
By Dr. Radha Nagarajan, Senior Vice President and Chief Technology Officer, Optical and Cloud Connectivity Group, Marvell
This article was originally published in Data Center Knowledge
People or servers?
Communities around the world are debating this question as they try to balance the plans of service providers and the concerns of residents.
Last year, the Greater London Authority told real estate developers that new housing projects in West London may not be able to go forward until 2035 because data centers have taken all of the excess grid capacity1. EirGrid2 said it won’t accept new data center applications until 2028. Beijing3 and Amsterdam have placed strict limits on new facilities. Cities in the southwest and elsewhere4, meanwhile, are increasingly worried about water consumption as mega-sized data centers can use over 1 million gallons a day5.
When you add in the additional computing cycles needed for AI and applications like ChatGPT, the outline of the conflict becomes more heated.
On the other hand, we know we can’t live without them. Modern society, with remote work, digital streaming and modern communications all depend on data centers. Data centers are also one of sustainability’s biggest success stories. Although workloads grew by approximately 10x in the last decade with the rise of SaaS and streaming, total power consumption stayed almost flat at around 1% to 1.5%6 of worldwide electricity thanks to technology advances, workload consolidation, and new facility designs. Try and name another industry that increased output by 10x with a relatively fixed energy diet?
-
June 27, 2023
高速光接続によるAIインフラの拡張
By Suhas Nayak, Senior Director of Solutions Marketing, Marvell

In the world of artificial intelligence (AI), where compute performance often steals the spotlight, there's an unsung hero working tirelessly behind the scenes. It's something that connects the dots and propels AI platforms to new frontiers. Welcome to the realm of optical connectivity, where data transfer becomes lightning-fast and AI's true potential is unleashed. But wait, before you dismiss the idea of optical connectivity as just another technical detail, let's pause and reflect. Think about it: every breakthrough in AI, every mind-bending innovation, is built on the shoulders of data—massive amounts of it. And to keep up with the insatiable appetite of AI workloads, we need more than just raw compute power. We need a seamless, high-speed highway that allows data to flow freely, powering AI platforms to conquer new challenges.
In this post, I’ll explain the importance of optical connectivity, particularly the role of DSP-based optical connectivity, in driving scalable AI platforms in the cloud. So, buckle up, get ready to embark on a journey where we unlock the true power of AI together.
-
June 13, 2023
FC-NVMeがHPEの次世代ブロックストレージの主流に
By Todd Owens, Field Marketing Director, Marvell
While Fibre Channel (FC) has been around for a couple of decades now, the Fibre Channel industry continues to develop the technology in ways that keep it in the forefront of the data center for shared storage connectivity. Always a reliable technology, continued innovations in performance, security and manageability have made Fibre Channel I/O the go-to connectivity option for business-critical applications that leverage the most advanced shared storage arrays.
A recent development that highlights the progress and significance of Fibre Channel is Hewlett Packard Enterprise’s (HPE) recent announcement of their latest offering in their Storage as a Service (SaaS) lineup with 32Gb Fibre Channel connectivity. HPE GreenLake for Block Storage MP powered by HPE Alletra Storage MP hardware features a next-generation platform connected to the storage area network (SAN) using either traditional SCSI-based FC or NVMe over FC connectivity. This innovative solution not only provides customers with highly scalable capabilities but also delivers cloud-like management, allowing HPE customers to consume block storage any way they desire – own and manage, outsource management, or consume on demand. HPE GreenLake for Block Storage powered by Alletra Storage MP
HPE GreenLake for Block Storage powered by Alletra Storage MPAt launch, HPE is providing FC connectivity for this storage system to the host servers and supporting both FC-SCSI and native FC-NVMe. HPE plans to provide additional connectivity options in the future, but the fact they prioritized FC connectivity speaks volumes of the customer demand for mature, reliable, and low latency FC technology.
-
March 10, 2023
次世代AI/MLシステムの高性能ファブリック向けに最適化された1.6T PAM4 DSP「Nova」を発表
By Kevin Koski, Product Marketing Director, Marvell
Last week, Marvell introduced Nova™, its latest, fourth generation PAM4 DSP for optical modules. It features breakthrough 200G per lambda optical bandwidth, which enables the module ecosystem to bring to market 1.6 Tbps pluggable modules. You can read more about it in the press release and the product brief.
In this post, I’ll explain why the optical modules enabled by Nova are the optimal solution to high-bandwidth connectivity in artificial intelligence and machine learning systems.
Let’s begin with a look into the architecture of supercomputers, also known as high-performance computing (HPC).
Historically, HPC has been realized using large-scale computer clusters interconnected by high-speed, low-latency communications networks to act as a single computer. Such systems are found in national or university laboratories and are used to simulate complex physics and chemistry to aid groundbreaking research in areas such as nuclear fusion, climate modeling and drug discovery. They consume megawatts of power.
The introduction of graphics processing units (GPUs) has provided a more efficient way to complete specific types of computationally intensive workloads. GPUs allow for the use of massive, multi-core parallel processing, while central processing units (CPUs) execute serial processes within each core. GPUs have both improved HPC performance for scientific research purposes and enabled a machine learning (ML) renaissance of sorts. With these advances, artificial intelligence (AI) is being pursued in earnest.
-
March 02, 2023
Introducing the 51.2T Teralynx 10, the Industry’s Lowest Latency Programmable Switch
By Amit Sanyal, Senior Director, Product Marketing, Marvell
If you’re one of the 100+ million monthly users of ChatGPT—or have dabbled with Google’s Bard or Microsoft’s Bing AI—you’re proof that AI has entered the mainstream consumer market.
And what’s entered the consumer mass-market will inevitably make its way to the enterprise, an even larger market for AI. There are hundreds of generative AI startups racing to make it so. And those responsible for making these AI tools accessible—cloud data center operators—are investing heavily to keep up with current and anticipated demand.
Of course, it’s not just the latest AI language models driving the coming infrastructure upgrade cycle. Operators will pay equal attention to improving general purpose cloud infrastructure too, as well as take steps to further automate and simplify operations.

To help operators meet their scaling and efficiency objectives, today Marvell introduces Teralynx® 10, a 51.2 Tbps programmable 5nm monolithic switch chip designed to address the operator bandwidth explosion while meeting stringent power- and cost-per-bit requirements. It’s intended for leaf and spine applications in next-generation data center networks, as well as AI/ML and high-performance computing (HPC) fabrics.
A single Teralynx 10 replaces twelve of the 12.8 Tbps generation, the last to see widespread deployment. The resulting savings are impressive: 80% power reduction for equivalent capacity.
-
February 21, 2023
マーベルと Aviz Networks、クラウドおよび企業データセンターへの SONiC 導入を推進するために協力
By Kant Deshpande, Director, Product Management, Marvell
Disaggregation is the future
Disaggregation—the decoupling of hardware and software—is arguably the future of networking. Disaggregation lets customers select best-of-breed hardware and software, enabling rapid innovation by separating the hardware and software development paths.Disaggregation started with server virtualization and is being adapted to storage and networking technology. In networking, disaggregation promises that any networking operating system (NOS) can be integrated with any switch silicon. Open source-standards like ONIE allow a networking switch to load and install any NOS during the boot process.
SONiC: the Linux of networking OS
Software for Open Networking in Cloud (SONiC) has been gaining momentum as the preferred open-source cloud-scale network operating system (NOS).In fact, Gartner predicts that by 2025, 40% of organizations that operate large data center networks (greater than 200 switches) will run SONiC in a production environment.[i] According to Gartner, due to readily expanding customer interest and a commercial ecosystem, there is a strong possibility SONiC will become analogous to Linux for networking operating systems in next three to six years.
-
February 14, 2023
次世代データセンターがネットワークに求める3つのもの
By Amit Sanyal, Senior Director, Product Marketing, Marvell
Data centers are arguably the most important buildings in the world. Virtually everything we do—from ordinary business transactions to keeping in touch with relatives and friends—is accomplished, or at least assisted, by racks of equipment in large, low-slung facilities.
And whether they know it or not, your family and friends are causing data center operators to spend more money. But it’s for a good cause: it allows your family and friends (and you) to continue their voracious consumption, purchasing and sharing of every kind of content—via the cloud.
Of course, it’s not only the personal habits of your family and friends that are causing operators to spend. The enterprise is equally responsible. They’re collecting data like never before, storing it in data lakes and applying analytics and machine learning tools—both to improve user experience, via recommendations, for example, and to process and analyze that data for economic gain. This is on top of the relentless, expanding adoption of cloud services.
-
November 28, 2022
驚異のハック - SONiCユーザーの心をつかむ
By Kishore Atreya, Director of Product Management, Marvell
Recently the Linux Foundation hosted its annual ONE Summit for open networking, edge projects and solutions. For the first time, this year’s event included a “mini-summit” for SONiC, an open source networking operating system targeted for data center applications that’s been widely adopted by cloud customers. A variety of industry members gave presentations, including Marvell’s very own Vijay Vyas Mohan, who presented on the topic of Extensible Platform Serdes Libraries. In addition, the SONiC mini-summit included a hackathon to motivate users and developers to innovate new ways to solve customer problems.
So, what could we hack?
At Marvell, we believe that SONiC has utility not only for the data center, but to enable solutions that span from edge to cloud. Because it’s a data center NOS, SONiC is not optimized for edge use cases. It requires an expensive bill of materials to run, including a powerful CPU, a minimum of 8 to 16GB DDR, and an SSD. In the data center environment, these HW resources contribute less to the BOM cost than do the optics and switch ASIC. However, for edge use cases with 1G to 10G interfaces, the cost of the processor complex, primarily driven by the NOS, can be a much more significant contributor to overall system cost. For edge disaggregation with SONiC to be viable, the hardware cost needs to be comparable to that of a typical OEM-based solution. Today, that’s not possible.
-
October 05, 2022
エネルギー効率の高いチップの設計
マーベル、ESGグローバルヘッド、レベッカオニールによる
今日はエネルギー効率の日である。 エネルギー、特に当社のチップに電力を供給するために必要な電力消費は、マーベルが最も重視していることである。 私たちの目標は、世代を重ねるごとに製品の消費電力を削減し、設定された機能を実現することである。
当社の製品は、クラウドや企業のデータセンター、5Gキャリアインフラ、自動車、産業用および企業用ネットワーキングにまたがるデータインフラに電力を供給する上で不可欠な役割を果たしている。 製品を設計する際には、新しい機能を提供する革新的な機能に焦点を当てると同時に、性能、容量、セキュリティを向上させ、最終的には製品使用時のエネルギー効率を改善する。
これらの技術革新は、世界のデータインフラをより効率的にし、ひいては気候変動への影響を軽減するのに役立つ。 お客様による当社製品の使用は、マーベルのスコープ3の温室効果ガス排出量に寄与している。
-
October 20, 2021
データセンター光ファイバー通信用低消費電力DSPベース・トランシーバー
By Radha Nagarajan, SVP and CTO, Optical and Copper Connectivity Business Group
As the volume of global data continues to grow exponentially, data center operators often confront a frustrating challenge: how to process a rising tsunami of terabytes within the limits of their facility’s electrical power supply – a constraint imposed by the physical capacity of the cables that bring electric power from the grid into their data center.
Fortunately, recent innovations in optical transmission technology – specifically, in the design of optical transceivers – have yielded tremendous gains in energy efficiency, which frees up electric power for more valuable computational work.
Recently, at the invitation of the Institute of Electrical and Electronics Engineers, my Marvell colleagues Ilya Lyubomirsky, Oscar Agazzi and I published a paper detailing these technological breakthroughs, titled Low Power DSP-based Transceivers for Data Center Optical Fiber Communications.
-
October 04, 2021
マーベルとロスアラモス国立研究所、Ethernet-Bunch-Of-Flash(EBOF)プラットフォームにより、データセンターにおけるHPCストレージワークロードの広帯域化能力を実証
By Khurram Malik, Senior Manager, Technical Marketing, Marvell
As data growth continues at a tremendously rapid pace, data centers have a strong demand for scalable, flexible, and high bandwidth utilization of storage solutions. Data centers need an efficient infrastructure to meet the growing requirements of next-generation high performance computing (HPC), machine learning (ML)/artificial intelligence (AI), composable disaggregated infrastructure (CDI), and storage expansion shelf applications which necessitate scalable, high performance, and cost-efficient technologies. Hyperscalers and storage OEMs tend to scale system-level performance linearly, driven by the number of NVMe SSDs that plug into the system. However, current NVMe-oF storage target Just-A-Bunch-Of-Flash (JBOF) architecture connects fast performance NVMe SSDs behind the JBOF components, causing system-level performance bottlenecks due to CPU, DRAM, PCIe switch and smartNIC bandwidth. In addition, JBOF architecture requires a fixed ratio of CPU and SSDs which results in underutilized resources. Another challenge with JBOF architecture is the scalability of CPU, DRAM, and smartNIC devices does not match the total bandwidth of corresponding NVMe SSDs in the system due to the overall system cost overhead and thus, impacts system-level performance.
Marvell introduced its industry-first NVMe-oF to NVMe SSD converter controller, the 88SN2400, as a data center storage solution application. It enables the industry to introduce EBOF storage architecture which provides an innovative approach to address JBOF architecture challenges, and truly disaggregate storage from the compute. EBOF architecture replaces JBOF bottleneck components like CPUs, DRAM and smartNICs with Ethernet switch and terminates NVMe-oF either on the bridge or Ethernet SSD. Marvell is enabling NAND vendors to offer Ethernet SSD products. EBOF architecture allows scalability, flexibility, and full utilization of PCIe NVMe drives. -
August 31, 2020
データセンターのアームプロセッサー
By Raghib Hussain, President, Products and Technologies
Last week, Marvell announced a change in our strategy for ThunderX, our Arm-based server-class processor product line. I’d like to take the opportunity to put some more context around that announcement, and our future plans in the data center market.
ThunderX is a product line that we started at Cavium, prior to our merger with Marvell in 2018. At Cavium, we had built many generations of successful processors for infrastructure applications, including our Nitrox security processor and OCTEON infrastructure processor. These processors have been deployed in the world’s most demanding data-plane applications such as firewalls, routers, SSL-acceleration, cellular base stations, and Smart NICs. Today, OCTEON is the most scalable and widely deployed multicore processor in the market. -
August 27, 2020
2020年にNVMe over Fabricのメリットを享受する方法
By Todd Owens, Field Marketing Director, Marvell
As native Non-volatile Memory Express (NVMe®) share-storage arrays continue enhancing our ability to store and access more information faster across a much bigger network, customers of all sizes – enterprise, mid-market and SMBs – confront a common question: what is required to take advantage of this quantum leap forward in speed and capacity?
Of course, NVMe technology itself is not new, and is commonly found in laptops, servers and enterprise storage arrays. NVMe provides an efficient command set that is specific to memory-based storage, provides increased performance that is designed to run over PCIe 3.0 or PCIe 4.0 bus architectures, and -- offering 64,000 command queues with 64,000 commands per queue -- can provide much more scalability than other storage protocols.
-
August 19, 2020
HPEにおけるMarvellイーサネット・アダプタの製品名変更について
By Todd Owens, Field Marketing Director, Marvell

Hewlett Packard Enterprise (HPE) recently updated its product naming protocol for the Ethernet adapters in its HPE ProLiant and HPE Apollo servers. Its new approach is to include the ASIC model vendor’s name in the HPE adapter’s product name. This commonsense approach eliminates the need for model number decoder rings on the part of Channel Partners and the HPE Field team and provides everyone with more visibility and clarity. This change also aligns more with the approach HPE has been taking with their “Open” adapters on HPE ProLiant Gen10 Plus servers. All of this is good news for everyone in the server sales ecosystem, including the end user. The products’ core SKU numbers remain the same, too, which is also good.
-
April 01, 2019
データセンターのアーキテクチャーに革命をもたらし、コネクテッドインテリジェンスに新たな時代をもたらします
寄稿 ジョージ ハーベイ, マーベルセミコンダクタ社 主任アーキテクト
現在確立されているメガスケールのクラウドデータセンターのアーキテクチャは、長年にわたるグローバル規模のデータ要求に対してのサポートは十分でしたが、ここへきて根本的な変化が起きています。 たとえば 5G、産業オートメーション、スマートシティ、自律走行車などでは、ネットワークエッジからデータに直接アクセスできるようにする必要性が高まっています。データセンターには、消費電力の低減、低遅延、小型化、およびコンポーザブル・インフラストラクチャなどの新しい要件をサポートするための新しいアーキテクチャが必要です。
コンポーザビリティは、データストレージリソースの分離を提供することで、データセンターの要件を満たすためのより柔軟で効率的なプラットフォームを提供します。しかし、それをサポートするために最先端のスイッチソリューションが必須となります。 12.8Tbps で動作可能な Marvell®Prestera CX 8500 イーサネットスイッチ製品ファミリーには、データセンターアーキテクチャを再定義するための 2 つの重要な革新技術が用意されています。ひとつはテラビットイーサネットルーターのスライス(FASTER)テクノロジーを使用していること、そして2つ目は Storage Aware Flow Engine(SAFE)テクノロジーを使用した転送アーキテクチャーを採用したことです。
FASTER および SAFE テクノロジーにより、Marvell® Prestera CX 8500 ファミリーはネットワーク全体のコストを 50% 以上も削減します。加えてより低い消費電力、小型および低遅延であることも大切なポイントです。そしてフローごとの完全な可視性が備えられていることで、輻輳の問題が発生している場所を正確に特定することができます。
Marvell Prestera CX 8500デバイスがデータセンターアーキテクチャーに対して革新的とも言えるアプローチについて、以下のビデオでご覧いただくことができます。
-
August 03, 2018
IOPとレイテンシー
By Marvell PR Team
Shared storage performance has significant impact on overall system performance. That’s why system administrators try to understand its performance and plan accordingly. Shared storage subsystems have three components: storage system software (host), storage network (switches and HBAs) and the storage array.
Storage performance can be measured at all three levels and aggregated to get to the subsystem performance. This can get quite complicated. Fortunately, storage performance can effectively be represented using two simple metrics: Input/Output operations per Second (IOPS) and Latency. Knowing these two values for a target workload, a user can optimize the performance of a storage system.
Let’s understand what these key factors are and how to use them to optimize of storage performance.
What is IOPS?
IOPS is a standard unit of measurement for the maximum number of reads and writes to a storage device for a given unit of time (e.g. seconds). IOPS represent the number of transactions that can be performed and not bytes of data. In order to calculate throughput, one would have to multiply the IOPS number by the block size used in the IO.
 IOPS is a neutral measure of performance and can be used in a benchmark where two systems are compared using same block sizes and read/write mix.
IOPS is a neutral measure of performance and can be used in a benchmark where two systems are compared using same block sizes and read/write mix. What is a Latency?
Latency is the total time for completing a requested operation and the requestor receiving a response. Latency includes the time spent in all subsystems, and is a good indicator of congestion in the system.
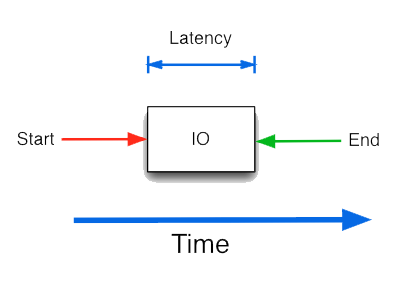 IOPS is a neutral measure of performance and can be used in a benchmark where two systems are compared using same block sizes and read/write mix.
IOPS is a neutral measure of performance and can be used in a benchmark where two systems are compared using same block sizes and read/write mix. What is a Latency?
Latency is the total time for completing a requested operation and the requestor receiving a response. Latency includes the time spent in all subsystems, and is a good indicator of congestion in the system.
Find more about Marvell’s QLogic Fibre Channel adapter technology at:
https://www.marvell.com/fibre-channel-adapters-and-controllers/qlogic-fibre-channel-adapters/
-
April 02, 2018
現在のネットワーク・テレメトリ要件の理解
By Tal Mizrahi, Feature Definition Architect, Marvell
There have, in recent years, been fundamental changes to the way in which networks are implemented, as data demands have necessitated a wider breadth of functionality and elevated degrees of operational performance. Accompanying all this is a greater need for accurate measurement of such performance benchmarks in real time, plus in-depth analysis in order to identify and subsequently resolve any underlying issues before they escalate.
The rapidly accelerating speeds and rising levels of complexity that are being exhibited by today’s data networks mean that monitoring activities of this kind are becoming increasingly difficult to execute. Consequently more sophisticated and inherently flexible telemetry mechanisms are now being mandated, particularly for data center and enterprise networks.
A broad spectrum of different options are available when looking to extract telemetry material, whether that be passive monitoring, active measurement, or a hybrid approach. An increasingly common practice is the piggy-backing of telemetry information onto the data packets that are passing through the network. This tactic is being utilized within both in-situ OAM (IOAM) and in-band network telemetry (INT), as well as in an alternate marking performance measurement (AM-PM) context.
At Marvell, our approach is to provide a diverse and versatile toolset through which a wide variety of telemetry approaches can be implemented, rather than being confined to a specific measurement protocol. To learn more about this subject, including longstanding passive and active measurement protocols, and the latest hybrid-based telemetry methodologies, please view the video below and download our white paper.
WHITE PAPER, Network Telemetry Solutions for Data Center and Enterprise Networks
-
January 11, 2018
世界中のデータを保管します
By Marvell PR Team
Storage is the foundation for a data-centric world, but how tomorrow’s data will be stored is the subject of much debate. What is clear is that data growth will continue to rise significantly. According to a report compiled by IDC titled ‘Data Age 2025’, the amount of data created will grow at an almost exponential rate. This amount is predicted to surpass 163 Zettabytes by the middle of the next decade (which is almost 8 times what it is today, and nearly 100 times what it was back in 2010). Increasing use of cloud-based services, the widespread roll-out of Internet of Things (IoT) nodes, virtual/augmented reality applications, autonomous vehicles, machine learning and the whole ‘Big Data’ phenomena will all play a part in the new data-driven era that lies ahead.
Further down the line, the building of smart cities will lead to an additional ramp up in data levels, with highly sophisticated infrastructure being deployed in order to alleviate traffic congestion, make utilities more efficient, and improve the environment, to name a few. A very large proportion of the data of the future will need to be accessed in real-time. This will have implications on the technology utilized and also where the stored data is situated within the network. Additionally, there are serious security considerations that need to be factored in, too.
So that data centers and commercial enterprises can keep overhead under control and make operations as efficient as possible, they will look to follow a tiered storage approach, using the most appropriate storage media so as to lower the related costs. Decisions on the media utilized will be based on how frequently the stored data needs to be accessed and the acceptable degree of latency. This will require the use of numerous different technologies to make it fully economically viable - with cost and performance being important factors.
There are now a wide variety of different storage media options out there. In some cases these are long established while in others they are still in the process of emerging. Hard disk drives (HDDs) in certain applications are being replaced by solid state drives (SSDs), and with the migration from SATA to NVMe in the SSD space, NVMe is enabling the full performance capabilities of SSD technology. HDD capacities are continuing to increase substantially and their overall cost effectiveness also adds to their appeal. The immense data storage requirements that are being warranted by the cloud mean that HDD is witnessing considerable traction in this space.
There are other forms of memory on the horizon that will help to address the challenges that increasing storage demands will set. These range from higher capacity 3D stacked flash to completely new technologies, such as phase-change with its rapid write times and extensive operational lifespan. The advent of NVMe over fabrics (NVMf) based interfaces offers the prospect of high bandwidth, ultra-low latency SSD data storage that is at the same time extremely scalable.
Marvell was quick to recognize the ever growing importance of data storage and has continued to make this sector a major focus moving forwards, and has established itself as the industry’s leading supplier of both HDD controllers and merchant SSD controllers.
Within a period of only 18 months after its release, Marvell managed to ship over 50 million of its 88SS1074 SATA SSD controllers with NANDEdge™ error-correction technology. Thanks to its award-winning 88NV11xx series of small form factor DRAM-less SSD controllers (based on a 28nm CMOS semiconductor process), the company is able to offer the market high performance NVMe memory controller solutions that are optimized for incorporation into compact, streamlined handheld computing equipment, such as tablet PCs and ultra-books. These controllers are capable of supporting reads speeds of 1600MB/s, while only drawing minimal power from the available battery reserves. Marvell offers solutions like its 88SS1092 NVMe SSD controller designed for new compute models that enable the data center to share storage data to further maximize cost and performance efficiencies.
The unprecedented growth in data means that more storage will be required. Emerging applications and innovative technologies will drive new ways of increasing storage capacity, improving latency and ensuring security. Marvell is in a position to offer the industry a wide range of technologies to support data storage requirements, addressing both SSD or HDD implementation and covering all accompanying interface types from SAS and SATA through to PCIe and NMVe.
 Check out www.marvell.com to learn more about how Marvell is storing the world’s data.
Check out www.marvell.com to learn more about how Marvell is storing the world’s data. -
2018年1月10日
マーベルは CES 2018 で Pixeom Edge Platform を使用して Google Cloud を Network Edge に拡張することによるエッジコンピューティングのデモンストレーションを行いました。
マーベル、シニア・ソフトウェア・プロダクト・ライン・マネージャー、マエン・スレイマン著
マルチギガビットネットワークの採用と次世代5Gネットワークの展開計画により、より多くのコンピューティングとストレージサービスがクラウドに移行するにつれて、利用可能なネットワーク帯域幅は拡大し続けるだろう。 ネットワークに接続されたIoT機器やモバイル機器上で実行されるアプリケーションは、ますますインテリジェント化し、計算負荷が高くなっている。 しかし、非常に多くのリソースがクラウドに流れているため、今日のネットワークには逼迫している。
次世代アーキテクチャでは、従来のクラウド集中型モデルではなく、ネットワークインフラ全体にインテリジェンスを分散させる必要がある。 高性能コンピューティングハードウェア(関連ソフトウェアを伴う)は、ネットワークのエッジに配置する必要がある。 分散型運用モデルは、エッジデバイスに必要なコンピュートとセキュリティ機能を提供し、魅力的なリアルタイムサービスを可能にし、車載、バーチャルリアリティ、産業用コンピューティングなどのアプリケーションに固有の待ち時間の問題を克服する必要がある。 このようなアプリケーションでは、高解像度のビデオやオーディオコンテンツの分析も必要となる。
Through use of its high performance ARMADA® embedded processors, Marvell is able to demonstrate a highly effective solution that will facilitate edge computing implementation on the Marvell MACCHIATObin™ community board using the ARMADA 8040 system on chip (SoC). At CES® 2018, Marvell and Pixeom teams will be demonstrating a fully effective, but not costly, edge computing system using the Marvell MACCHIATObin community board in conjunction with the Pixeom Edge Platform to extend functionality of Google Cloud Platform™ services at the edge of the network. The Marvell MACCHIATObin community board will run Pixeom Edge Platform software that is able to extend the cloud capabilities by orchestrating and running Docker container-based micro-services on the Marvell MACCHIATObin community board.
現在、データ量の多い高解像度のビデオコンテンツを分析目的でクラウドに送信することは、ネットワークインフラに大きな負担をかけ、リソースを大量に消費し、コストもかかることが判明している。 Marvell MACCHIATObinハードウェアを基盤として、Pixeomはネットワークエッジでビデオ分析機能を提供するコンテナベースのエッジコンピューティングソリューションのデモを行う。 このユニークなハードウェアとソフトウェアの組み合わせは、より多くのプロセッシングリソースとストレージリソースをネットワークのエッジに配置することを可能にする、高度に最適化されたわかりやすい方法を提供する。 この技術は、運用効率レベルを大幅に向上させ、待ち時間を短縮することができる。
The Marvell and Pixeom demonstration deploys Google TensorFlow™ micro-services at the network edge to enable a variety of different key functions, including object detection, facial recognition, text reading (for name badges, license plates, etc.) and intelligent notifications (for security/safety alerts). This technology encompasses the full scope of potential applications, covering everything from video surveillance and autonomous vehicles, right through to smart retail and artificial intelligence. Pixeom offers a complete edge computing solution, enabling cloud service providers to package, deploy, and orchestrate containerized applications at scale, running on premise “Edge IoT Cores.” To accelerate development, Cores come with built-in machine learning, FaaS, data processing, messaging, API management, analytics, offloading capabilities to Google Cloud, and more.
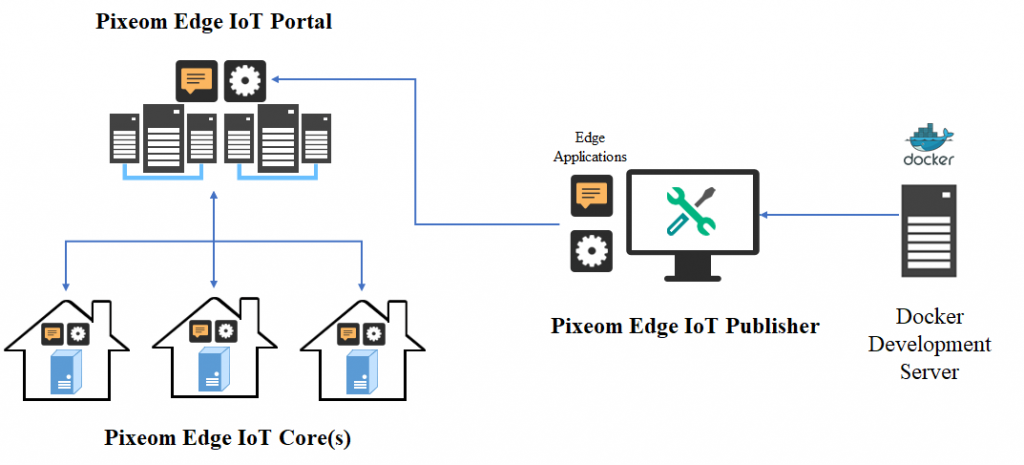 The MACCHIATObin community board is using Marvell’s ARMADA 8040 processor and has a 64-bit ARMv8 quad-core processor core (running at up to 2.0GHZ), and supports up to 16GB of DDR4 memory and a wide array of different I/Os. Through use of Linux® on the Marvell MACCHIATObin board, the multifaceted Pixeom Edge IoT platform can facilitate implementation of edge computing servers (or cloudlets) at the periphery of the cloud network. Marvell will be able to show the power of this popular hardware platform to run advanced machine learning, data processing, and IoT functions as part of Pixeom’s demo. The role-based access features of the Pixeom Edge IoT platform also mean that developers situated in different locations can collaborate with one another in order to create compelling edge computing implementations. Pixeom supplies all the edge computing support needed to allow Marvell embedded processors users to establish their own edge-based applications, thus offloading operations from the center of the network.
The MACCHIATObin community board is using Marvell’s ARMADA 8040 processor and has a 64-bit ARMv8 quad-core processor core (running at up to 2.0GHZ), and supports up to 16GB of DDR4 memory and a wide array of different I/Os. Through use of Linux® on the Marvell MACCHIATObin board, the multifaceted Pixeom Edge IoT platform can facilitate implementation of edge computing servers (or cloudlets) at the periphery of the cloud network. Marvell will be able to show the power of this popular hardware platform to run advanced machine learning, data processing, and IoT functions as part of Pixeom’s demo. The role-based access features of the Pixeom Edge IoT platform also mean that developers situated in different locations can collaborate with one another in order to create compelling edge computing implementations. Pixeom supplies all the edge computing support needed to allow Marvell embedded processors users to establish their own edge-based applications, thus offloading operations from the center of the network. 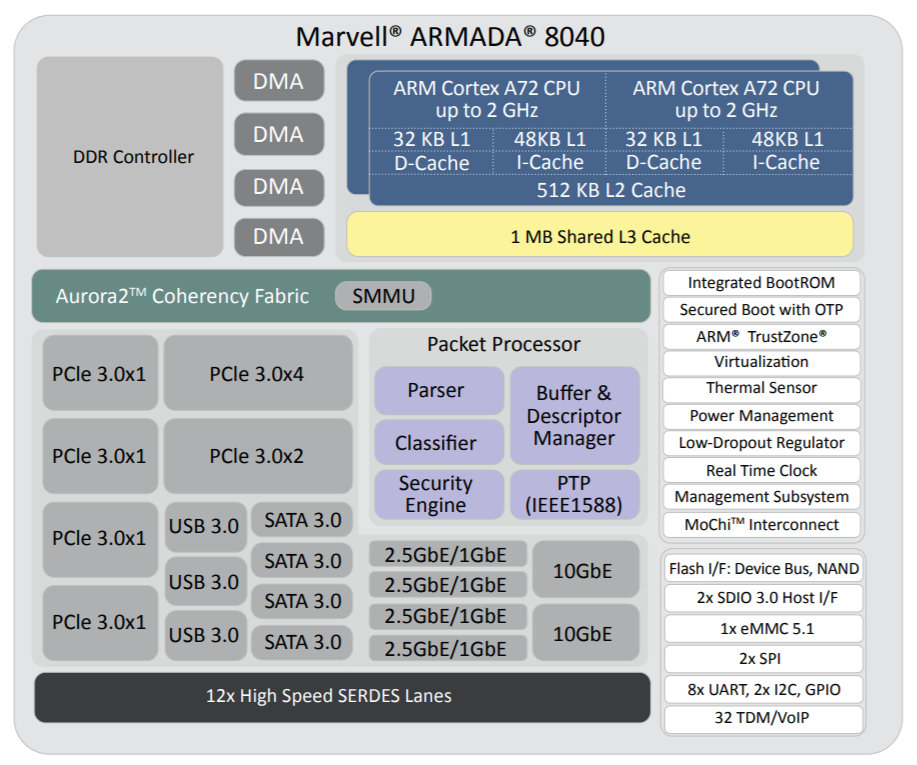 Marvell will also be demonstrating the compatibility of its technology with the Google Cloud platform, which enables the management and analysis of deployed edge computing resources at scale. Here, once again the MACCHIATObin board provides the hardware foundation needed by engineers, supplying them with all the processing, memory and connectivity required.
Marvell will also be demonstrating the compatibility of its technology with the Google Cloud platform, which enables the management and analysis of deployed edge computing resources at scale. Here, once again the MACCHIATObin board provides the hardware foundation needed by engineers, supplying them with all the processing, memory and connectivity required. Those visiting Marvell’s suite at CES (Venetian, Level 3 - Murano 3304, 9th-12th January 2018, Las Vegas) will be able to see a series of different demonstrations of the MACCHIATObin community board running cloud workloads at the network edge. Make sure you come by!
-
2018年1月10日
Moving the World’s Data
マーベル、PR チーム
The way in which data is moved via wireline and wireless connectivity is going through major transformations. The dynamics that are causing these changes are being seen across a broad cross section of different sectors.
Within our cars, the new features and functionality that are being incorporated mean that the traditional CAN and LIN based communication technology is no longer adequate. More advanced in-vehicle networking needs to be implemented which is capable of supporting multi-Gigabit data rates, in order to cope with the large quantities of data that high resolution cameras, more sophisticated infotainment, automotive radar and LiDAR will produce. With CAN, LIN and other automotive networking technologies not offering viable upgrade paths, it is clear that Ethernet will be the basis of future in-vehicle network infrastructure - offering the headroom needed as automobile design progresses towards the long term goal of fully autonomous vehicles. Marvell is already proving itself to be ahead of the game here, following the announcement of the industry’s first secure automotive gigabit Ethernet switch, which delivers the speeds now being required by today’s data-heavy automotive designs, while also ensuring secure operation is maintained and the threat of hacking or denial of service (DoS) attacks is mitigated.
Within the context of modern factories and processing facilities, the arrival of Industry 4.0 will allow greater levels of automation, through use of machine-to-machine (M2M) communication. This communication can enable the access of data — data that is provided by a multitude of different sensor nodes distributed throughout the site. The ongoing in-depth analysis of this data is designed to ultimately bring improvements in efficiency and productivity for the modern factory environment. Ethernet capable of supporting Gigabit data rates has shown itself to be the prime candidate and it is already experiencing extensive implementation. Not only will this meet the speed and bandwidth requirements needed, but it also has the robustness that is mandatory in such settings (dealing with high temperatures, ESD strikes, exposure to vibrations, etc.) and the low latency characteristics that are essential for real-time control/analysis. Marvell has developed highly sophisticated Gigabit Ethernet transceivers with elevated performance that are targeted at such applications.
Within data centers things are changing too, but in this case the criteria involved are somewhat different. Here it is more about how to deal with the large volumes of data involved, while keeping the associated capital and operational expenses in check. Marvell has been championing a more cost effective and streamlined approach through its Prestera® PX Passive Intelligent Port Extender (PIPE) products. These present data center engineers with a modular approach to deploy network infrastructure that meets their specific requirements, rather than having to add further layers of complexity unnecessarily that will only serve to raise the cost and the power consumption. The result is a fully scalable, more economical and energy efficient solution.
ワイヤレス領域では、家庭、オフィス、自治体、小売店などの環境において、WLANハードウェアに対するプレッシャーがますます大きくなっている。 ネットワーク事業者やサービスプロバイダーは、ユーザー密度の増加や全体的なデータ容量の増加だけでなく、ユーザーの行動にも現在起きている変化に対応する必要がある。 Wi-Fi接続は、もはやデータをダウンロードするためだけのものではなく、データのアップロードがますます重要な考慮事項となるだろう。 これは、拡張リアリティゲーム、HDビデオコンテンツの共有、クラウドベースの創作活動など、さまざまな用途に必要とされる。 これに対処するため、Wi-Fi技術は、アップリンクとダウンリンクの帯域幅能力を向上させる必要がある。
The introduction of the much anticipated 802.11ax protocol is set to radically change how Wi-Fi is implemented. Not only will this allow far greater user densities to be supported (thereby meeting the coverage demands of places where large numbers of people are in need of Internet access, such as airports, sports stadia and concert venues), it also offers greater uplink/downlink data capacity - supporting multi-Gigabit operation in both directions. Marvell is looking to drive things forward via its portfolio of recently unveiled multi-Gigabit 802.11ax Wi-Fi system-on-chips (SoCs), which are the first in the industry to have orthogonal frequency-division multiple access (OFDMA) and multi-user MIMO operation on both the downlink and the uplink.
 Check out www.marvell.com to learn more about how Marvell is moving the world’s data.
Check out www.marvell.com to learn more about how Marvell is moving the world’s data. -
November 06, 2017
The USR-Alliance – Enabling an Open Multi-Chip Module (MCM) Ecosystem
By Gidi Navon, Senior Principal Architect, Marvell
 The semiconductor industry is witnessing exponential growth and rapid changes to its bandwidth requirements, as well as increasing design complexity, emergence of new processes and integration of multi-disciplinary technologies. All this is happening against a backdrop of shorter development cycles and fierce competition. Other technology-driven industry sectors, such as software and hardware, are addressing similar challenges by creating open alliances and open standards. This blog does not attempt to list all the open alliances that now exist -- the Open Compute Project, Open Data Path and the Linux Foundation are just a few of the most prominent examples. One technological area that still hasn’t embraced such open collaboration is Multi-Chip-Module (MCM), where multiple semiconductor dies are packaged together, thereby creating a combined system in a single package.
The semiconductor industry is witnessing exponential growth and rapid changes to its bandwidth requirements, as well as increasing design complexity, emergence of new processes and integration of multi-disciplinary technologies. All this is happening against a backdrop of shorter development cycles and fierce competition. Other technology-driven industry sectors, such as software and hardware, are addressing similar challenges by creating open alliances and open standards. This blog does not attempt to list all the open alliances that now exist -- the Open Compute Project, Open Data Path and the Linux Foundation are just a few of the most prominent examples. One technological area that still hasn’t embraced such open collaboration is Multi-Chip-Module (MCM), where multiple semiconductor dies are packaged together, thereby creating a combined system in a single package. The MCM concept has been around for a while, generating multiple technological and market benefits, including:
- Improved yield - Instead of creating large monolithic dies with low yield and higher cost (which sometimes cannot even be fabricated), splitting the silicon into multiple die can significantly improve the yield of each building block and the combined solution. Better yield consequently translates into reductions in costs.
- Optimized process - The final MCM product is a mix-and-match of units in different fabrication processes which enables optimizing of the process selection for specific IP blocks with similar characteristics.
- Multiple fabrication plants - Different fabs, each with its own unique capabilities, can be utilized to create a given product.
- Product variety - New products are easily created by combining different numbers and types of devices to form innovative and cost‑optimized MCMs.
- Short product cycle time - Dies can be upgraded independently, which promotes ease in the addition of new product capabilities and/or the ability to correct any issues within a given die. For example, integrating a new type of I/O interface can be achieved without having to re-spin other parts of the solution that are stable and don’t require any change (thus avoiding waste of time and money).
- Economy of scale - Each die can be reused in multiple applications and products, increasing its volume and yield as well as the overall return on the initial investment made in its development.
Sub-dividing large semiconductor devices and mounting them on an MCM has now become the new printed circuit board (PCB) - providing smaller footprint, lower power, higher performance and expanded functionality.
Now, imagine that the benefits listed above are not confined to a single chip vendor, but instead are shared across the industry as a whole. By opening and standardizing the interface between dies, it is possible to introduce a true open platform, wherein design teams in different companies, each specializing in different technological areas, are able to create a variety of new products beyond the scope of any single company in isolation.
This is where the USR Alliance comes into action. The alliance has defined an Ultra Short Reach (USR) link, optimized for communication across the very short distances between the components contained in a single package. This link provides high bandwidth with less power and smaller die size than existing very short reach (VSR) PHYs which cross package boundaries and connectors and need to deal with challenges that simply don’t exist inside a package. The USR PHY is based on a multi-wire differential signaling technique optimized for MCM environments.
There are many applications in which the USR link can be implemented. Examples include CPUs, switches and routers, FPGAs, DSPs, analog components and a variety of long reach electrical and optical interfaces.
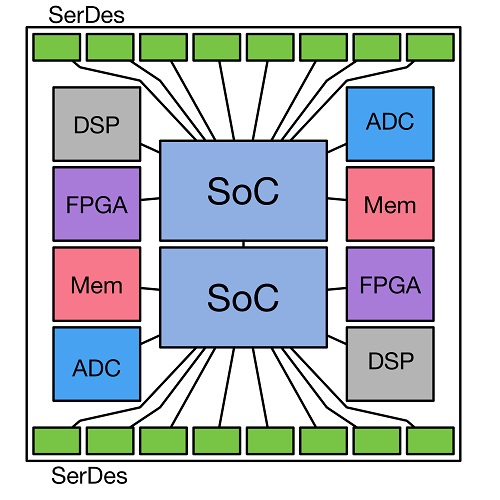 図 1:Example of a possible MCM layout
図 1:Example of a possible MCM layout Marvell is an active promoter member of the USR Alliance and is working to create an ecosystem of interoperable components, interconnects, protocols and software that will help the semiconductor industry bring more value to the market. The alliance is working on creating PHY, MAC and software standards and interoperability agreements in collaboration with the industry and other standards development organizations, and is promoting the development of a full ecosystem around USR applications (including certification programs) to ensure widespread interoperability.
To learn more about the USR Alliance visit: www.usr-alliance.org
-
October 03, 2017
Wi-Fi 20周年のお祝い – パート I
By Prabhu Loganathan, Senior Director of Marketing for Connectivity Business Unit, Marvell
You can't see it, touch it, or hear it - yet Wi-Fi® has had a tremendous impact on the modern world - and will continue to do so. From our home wireless networks, to offices and public spaces, the ubiquity of high speed connectivity without reliance on cables has radically changed the way computing happens. It would not be much of an exaggeration to say that because of ready access to Wi-Fi, we are consequently able to lead better lives - using our laptops, tablets and portable electronics goods in a far more straightforward, simplistic manner with a high degree of mobility, no longer having to worry about a complex tangle of wires tying us down.
Though it may be hard to believe, it is now two decades since the original 802.11 standard was ratified by the IEEE®. This first in a series of blogs will look at the history of Wi-Fi to see how it has overcome numerous technical challenges and evolved into the ultra-fast, highly convenient wireless standard that we know today. We will then go on to discuss what it may look like tomorrow.
Unlicensed Beginnings
While we now think of 802.11 wireless technology as predominantly connecting our personal computing devices and smartphones to the Internet, it was in fact initially invented as a means to connect up humble cash registers. In the late 1980s, NCR Corporation, a maker of retail hardware and point-of-sale (PoS) computer systems, had a big problem. Its customers - department stores and supermarkets - didn't want to dig up their floors each time they changed their store layout.
A recent ruling that had been made by the FCC, which opened up certain frequency bands as free to use, inspired what would be a game-changing idea. By using wireless connections in the unlicensed spectrum (rather than conventional wireline connections), electronic cash registers and PoS systems could be easily moved around a store without the retailer having to perform major renovation work.
Soon after this, NCR allocated the project to an engineering team out of its Netherlands office. They were set the challenge of creating a wireless communication protocol. These engineers succeeded in developing ‘WaveLAN’, which would be recognized as the precursor to Wi-Fi. Rather than preserving this as a purely proprietary protocol, NCR could see that by establishing it as a standard, the company would be able to position itself as a leader in the wireless connectivity market as it emerged. By 1990, the IEEE 802.11 working group had been formed, based on wireless communication in unlicensed spectra.
Using what were at the time innovative spread spectrum techniques to reduce interference and improve signal integrity in noisy environments, the original incarnation of Wi-Fi was finally formally standardized in 1997. It operated with a throughput of just 2 Mbits/s, but it set the foundations of what was to come.
Wireless Ethernet
Though the 802.11 wireless standard was released in 1997, it didn't take off immediately. Slow speeds and expensive hardware hampered its mass market appeal for quite a while - but things were destined to change. 10 Mbit/s Ethernet was the networking standard of the day. The IEEE 802.11 working group knew that if they could equal that, they would have a worthy wireless competitor. In 1999, they succeeded, creating 802.11b. This used the same 2.4 GHz ISM frequency band as the original 802.11 wireless standard, but it raised the throughput supported considerably, reaching 11 Mbits/s. Wireless Ethernet was finally a reality.
Soon after 802.11b was established, the IEEE working group also released 802.11a, an even faster standard. Rather than using the increasingly crowded 2.4 GHz band, it ran on the 5 GHz band and offered speeds up to a lofty 54 Mbits/s.
Because it occupied the 5 GHz frequency band, away from the popular (and thus congested) 2.4 GHz band, it had better performance in noisy environments; however, the higher carrier frequency also meant it had reduced range compared to 2.4 GHz wireless connectivity. Thanks to cheaper equipment and better nominal ranges, 802.11b proved to be the most popular wireless standard by far. But, while it was more cost effective than 802.11a, 802.11b still wasn't at a low enough price bracket for the average consumer. Routers and network adapters would still cost hundreds of dollars.
That all changed following a phone call from Steve Jobs. Apple was launching a new line of computers at that time and wanted to make wireless networking functionality part of it. The terms set were tough - Apple expected to have the cards at a $99 price point, but of course the volumes involved could potentially be huge. Lucent Technologies, which had acquired NCR by this stage, agreed.
While it was a difficult pill to swallow initially, the Apple deal finally put Wi-Fi in the hands of consumers and pushed it into the mainstream. PC makers saw Apple computers beating them to the punch and wanted wireless networking as well. Soon, key PC hardware makers including Dell, Toshiba, HP and IBM were all offering Wi-Fi.
Microsoft also got on the Wi-Fi bandwagon with Windows XP. Working with engineers from Lucent, Microsoft made Wi-Fi connectivity native to the operating system. Users could get wirelessly connected without having to install third party drivers or software. With the release of Windows XP, Wi-Fi was now natively supported on millions of computers worldwide - it had officially made it into the ‘big time’.
This blog post is the first in a series that charts the eventful history of Wi-Fi. The second part, which is coming soon, will bring things up to date and look at current Wi-Fi implementations.
-
September 18, 2017
データセンターをアップグレードする際のコスト効率をモジュラーネットワーキングによって改善
By Yaron Zimmerman, Senior Staff Product Line Manager, Marvell
Exponential growth in data center usage has been responsible for driving a huge amount of investment in the networking infrastructure used to connect virtualized servers to the multiple services they now need to accommodate. To support the server-to-server traffic that virtualized data centers require, the networking spine will generally rely on high capacity 40 Gbit/s and 100 Gbit/s switch fabrics with aggregate throughputs now hitting 12.8 Tbit/s. But the ‘one size fits all’ approach being employed to develop these switch fabrics quickly leads to a costly misalignment for data center owners. They need to find ways to match the interfaces on individual storage units and server blades that have already been installed with the switches they are buying to support their scale-out plans.
The top-of-rack (ToR) switch provides one way to match the demands of the server equipment and the network infrastructure. The switch can aggregate the data from lower speed network interfaces and so act as a front-end to the core network fabric. But such switches tend to be far more complex than is actually needed - often derived from older generations of core switch fabric. They perform a level of switching that is unnecessary and, as a result, are not cost effective when they are primarily aggregating traffic on its way to the core network’s 12.8 Tbits/s switching engines. The heightened expense manifests itself not only in terms of hardware complexity and the issues of managing an extra network tier, but also in relation to power and air-conditioning. It is not unusual to find five or more fans inside each unit being used to cool the silicon switch. There is another way to support the requirements of data center operators which consumes far less power and money, while also offering greater modularity and flexibility too.
Providing a means by which to overcome the high power and cost associated with traditional ToR switch designs, the IEEE 802.1BR standard for port extenders makes it possible to implement a bridge between a core network interface and a number of port extenders that break out connections to individual edge devices. An attractive feature of this standard is the ability to allow port extenders to be cascaded, for even greater levels of modularity. As a result, many lower speed ports, of 1 Gbit/s and 10 Gbits/s, can be served by one core network port (supporting 40 Gbits/s or 100 Gbits/s operation) through a single controlling bridge device.
With a simpler, more modular approach, the passive intelligent port extender (PIPE) architecture that has been developed by Marvell leads to next generation rack units which no longer call for the inclusion of any fans for thermal management purposes. Reference designs have already been built that use a simple 65W open-frame power supply to feed all the devices required even in a high-capacity, 48-ports of 10 Gbits/s. Furthermore, the equipment dispenses with the need for external management. The management requirements can move to the core 12.8 Tbit/s switch fabric, providing further savings in terms of operational expenditure. It is a demonstration of exactly how a more modular approach can greatly improve the efficiency of today's and tomorrow's data center implementations.
-
August 31, 2017
ハードウェア暗号化によって組込み型ストレージを保護
By Jeroen Dorgelo, Director of Strategy, Storage Group, Marvell
For industrial, military and a multitude of modern business applications, data security is of course incredibly important. While software based encryption often works well for consumer and some enterprise environments, in the context of the embedded systems used in industrial and military applications, something that is of a simpler nature and is intrinsically more robust is usually going to be needed.
Self encrypting drives utilize on-board cryptographic processors to secure data at the drive level. This not only increases drive security automatically, but does so transparently to the user and host operating system. By automatically encrypting data in the background, they thus provide the simple to use, resilient data security that is required by embedded systems.
Embedded vs Enterprise Data Security
Both embedded and enterprise storage often require strong data security. Depending on the industry sectors involved this is often related to the securing of customer (or possibly patient) privacy, military data or business data. However that is where the similarities end. Embedded storage is often used in completely different ways from enterprise storage, thereby leading to distinctly different approaches to how data security is addressed.
Enterprise storage usually consists of racks of networked disk arrays in a data center, while embedded storage is often simply a solid state drive (SSD) installed into an embedded computer or device. The physical security of the data center can be controlled by the enterprise, and software access control to enterprise networks (or applications) is also usually implemented. Embedded devices, on the other hand - such as tablets, industrial computers, smartphones, or medical devices - are often used in the field, in what are comparatively unsecure environments. Data security in this context has no choice but to be implemented down at the device level.
Hardware Based Full Disk Encryption
For embedded applications where access control is far from guaranteed, it is all about securing the data as automatically and transparently as possible.
Full disk, hardware based encryption has shown itself to be the best way of achieving this goal. Full disk encryption (FDE) achieves high degrees of both security and transparency by encrypting everything on a drive automatically. Whereas file based encryption requires users to choose files or folders to encrypt, and also calls for them to provide passwords or keys to decrypt them, FDE works completely transparently. All data written to the drive is encrypted, yet, once authenticated, a user can access the drive as easily as an unencrypted one. This not only makes FDE much easier to use, but also means that it is a more reliable method of encryption, as all data is automatically secured. Files that the user forgets to encrypt or doesn’t have access to (such as hidden files, temporary files and swap space) are all nonetheless automatically secured.
While FDE can be achieved through software techniques, hardware based FDE performs better, and is inherently more secure. Hardware based FDE is implemented at the drive level, in the form of a self encrypting SSD. The SSD controller contains a hardware cryptographic engine, and also stores private keys on the drive itself.
Because software based FDE relies on the host processor to perform encryption, it is usually slower - whereas hardware based FDE has much lower overhead as it can take advantage of the drive’s integrated crypto-processor. Hardware based FDE is also able to encrypt the master boot record of the drive, which conversely software based encryption is unable to do.
Hardware centric FDEs are transparent to not only the user, but also the host operating system. They work transparently in the background and no special software is needed to run them. Besides helping to maximize ease of use, this also means sensitive encryption keys are kept separate from the host operating system and memory, as all private keys are stored on the drive itself.
Improving Data Security
Besides providing the transparent, easy to use encryption that is now being sought, hardware- based FDE also has specific benefits for data security in modern SSDs. NAND cells have a finite service life and modern SSDs use advanced wear leveling algorithms to extend this as much as possible. Instead of overwriting the NAND cells as data is updated, write operations are constantly moved around a drive, often resulting in multiple copies of a piece of data being spread across an SSD as a file is updated. This wear leveling technique is extremely effective, but it makes file based encryption and data erasure much more difficult to accomplish, as there are now multiple copies of data to encrypt or erase.
FDE solves both these encryption and erasure issues for SSDs. Since all data is encrypted, there are not any concerns about the presence of unencrypted data remnants. In addition, since the encryption method used (which is generally 256-bit AES) is extremely secure, erasing the drive is as simple to do as erasing the private keys.
Solving Embedded Data Security
Embedded devices often present considerable security challenges to IT departments, as these devices are often used in uncontrolled environments, possibly by unauthorized personnel. Whereas enterprise IT has the authority to implement enterprise wide data security policies and access control, it is usually much harder to implement these techniques for embedded devices situated in industrial environments or used out in the field.
The simple solution for data security in embedded applications of this kind is hardware based FDE. Self encrypting drives with hardware crypto-processors have minimal processing overhead and operate completely in the background, transparent to both users and host operating systems. Their ease of use also translates into improved security, as administrators do not need to rely on users to implement security policies, and private keys are never exposed to software or operating systems.
-
July 17, 2017
イーサネット規模の最適化
寄稿 ジョージ ハーベイ, マーベルセミコンダクタ社 主任アーキテクト
Implementation of cloud infrastructure is occurring at a phenomenal rate, outpacing Moore's Law. Annual growth is believed to be 30x and as much 100x in some cases. In order to keep up, cloud data centers are having to scale out massively, with hundreds, or even thousands of servers becoming a common sight.
At this scale, networking becomes a serious challenge. More and more switches are required, thereby increasing capital costs, as well as management complexity. To tackle the rising expense issues, network disaggregation has become an increasingly popular approach. By separating the switch hardware from the software that runs on it, vendor lock-in is reduced or even eliminated. OEM hardware could be used with software developed in-house, or from third party vendors, so that cost savings can be realized.
Though network disaggregation has tackled the immediate problem of hefty capital expenditures, it must be recognized that operating expenditures are still high. The number of managed switches basically stays the same. To reduce operating costs, the issue of network complexity has to also be tackled.
Network Disaggregation
Almost every application we use today, whether at home or in the work environment, connects to the cloud in some way. Our email providers, mobile apps, company websites, virtualized desktops and servers, all run on servers in the cloud.
For these cloud service providers, this incredible growth has been both a blessing and a challenge. As demand increases, Moore's law has struggled to keep up. Scaling data centers today involves scaling out - buying more compute and storage capacity, and subsequently investing in the networking to connect it all. The cost and complexity of managing everything can quickly add up.
Until recently, networking hardware and software had often been tied together. Buying a switch, router or firewall from one vendor would require you to run their software on it as well. Larger cloud service providers saw an opportunity. These players often had no shortage of skilled software engineers. At the massive scales they ran at, they found that buying commodity networking hardware and then running their own software on it would save them a great deal in terms of Capex.
This disaggregation of the software from the hardware may have been financially attractive, however it did nothing to address the complexity of the network infrastructure. There was still a great deal of room to optimize further.
802.1BR
Today's cloud data centers rely on a layered architecture, often in a fat-tree or leaf-spine structural arrangement. Rows of racks, each with top-of-rack (ToR) switches, are then connected to upstream switches on the network spine. The ToR switches are, in fact, performing simple aggregation of network traffic. Using relatively complex, energy consuming switches for this task results in a significant capital expense, as well as management costs and no shortage of headaches.
Through the port extension approach, outlined within the IEEE 802.1BR standard, the aim has been to streamline this architecture. By replacing ToR switches with port extenders, port connectivity is extended directly from the rack to the upstream. Management is consolidated to the fewer number of switches which are located at the upper layer network spine, eliminating the dozens or possibly hundreds of switches at the rack level.
The reduction in switch management complexity of the port extender approach has been widely recognized, and various network switches on the market now comply with the 802.1BR standard. However, not all the benefits of this standard have actually been realized.
The Next Step in Network Disaggregation
Though many of the port extenders on the market today fulfill 802.1BR functionality, they do so using legacy components. Instead of being optimized for 802.1BR itself, they rely on traditional switches. This, as a consequence impacts upon the potential cost and power benefits that the new architecture offers.
Designed from the ground up for 802.1BR, Marvell's Passive Intelligent Port Extender (PIPE) offering is specifically optimized for this architecture. PIPE is interoperable with 802.1BR compliant upstream bridge switches from all the industry’s leading OEMs. It enables fan-less, cost efficient port extenders to be deployed, which thereby provide upfront savings as well as ongoing operational savings for cloud data centers. Power consumption is lowered and switch management complexity is reduced by an order of magnitude
The first wave in network disaggregation was separating switch software from the hardware that it ran on. 802.1BR's port extender architecture is bringing about the second wave, where ports are decoupled from the switches which manage them. The modular approach to networking discussed here will result in lower costs, reduced energy consumption and greatly simplified network management.
-
July 07, 2017
3.2T スイッチベース・アーキテクチャの製品寿命延長
By Yaron Zimmerman, Senior Staff Product Line Manager, Marvell and Yaniv Kopelman, Networking and Connectivity CTO, Marvell
The growth witnessed in the expanse of data centers has been completely unprecedented. This has been driven by the exponential increases in cloud computing and cloud storage demand that is now being witnessed. While Gigabit switches proved more than sufficient just a few years ago, today, even 3.2 Terabit (3.2T) switches, which currently serve as the fundamental building blocks upon which data center infrastructure is constructed, are being pushed to their full capacity.
While network demands have increased, Moore's law (which effectively defines the semiconductor industry) has not been able to keep up. Instead of scaling at the silicon level, data centers have had to scale out. This has come at a cost though, with ever increasing capital, operational expenditure and greater latency all resulting. Facing this challenging environment, a different approach is going to have to be taken. In order to accommodate current expectations economically, while still also having the capacity for future growth, data centers (as we will see) need to move towards a modularized approach.
 Scaling out the datacenter
Scaling out the datacenter Data centers are destined to have to contend with demands for substantially heightened network capacity - as a greater number of services, plus more data storage, start migrating to the cloud. This increase in network capacity, in turn, results in demand for more silicon to support it.
To meet increasing networking capacity, data centers are buying ever more powerful Top-of-Rack (ToR) leaf switches. In turn these are consuming more power - which impacts on the overall power budget and means that less power is available for the data center servers. Not only does this lead to power being unnecessarily wasted, in addition it will push the associated thermal management costs and the overall Opex upwards. As these data centers scale out to meet demand, they're often having to add more complex hierarchical structures to their architecture as well - thereby increasing latencies for both north-south and east-west traffic in the process.
The price of silicon per gate is not going down either. We used to enjoy cost reductions as process sizes decreased from 90 nm, to 65 nm, to 40 nm. That is no longer strictly true however. As we see process sizes go down from 28 nm node sizes, yields are decreasing and prices are consequently going up. To address the problems of cloud-scale data centers, traditional methods will not be applicable. Instead, we need to take a modularized approach to networking.
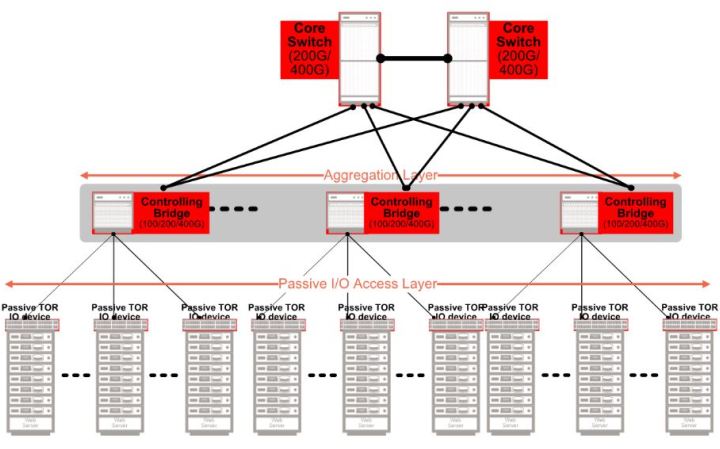
PIPEs and Bridges
Today's data centers often run on a multi-tiered leaf and spine hierarchy. Racks with ToR switches connect to the network spine switches. These, in turn, connect to core switches, which subsequently connect to the Internet. Both the spine and the top of the rack layer elements contain full, managed switches.
By following a modularized approach, it is possible to remove the ToR switches and replace them with simple IO devices - port extenders specifically. This effectively extends the IO ports of the spine switch all the way down to the ToR. What results is a passive ToR that is unmanaged. It simply passes the packets to the spine switch. Furthermore, by taking a whole layer out of the management hierarchy, the network becomes flatter and is thus considerably easier to manage.
The spine switch now acts as the controlling bridge. It is able to manage the layer which was previously taken care of by the ToR switch. This means that, through such an arrangement, it is possible to disaggregate the IO ports of the network that were previously located at the ToR switch, from the logic at the spine switch which manages them. This innovative modularized approach is being facilitated by the increasing number of Port Extenders and Control Bridges now being made available from Marvell that are compatible with the IEEE 802.1BR bridge port extension standard.
Solving Data Center Scaling Challenges
The modularized port-extender and control bridge approach allows data centers to address the full length and breadth of scaling challenges. Port extenders solve the latency by flattening the hierarchy. Instead of having conventional ‘leaf’ and ‘spine’ tiers, the port extender acts to simply extend the IO ports of the spine switch to the ToR. Each server in the rack has a near-direct connection to the managing switch. This improves latency for north-south bound traffic.
The port extender also functions to aggregate traffic from 10 Gbit Ethernet ports into higher throughput outputs, allowing for terabit switches which only have 25, 40, or 100 Gbit Ethernet ports, to communicate directly with 10 Gbit Ethernet edge devices. The passive port extender is a greatly simplified device compared to a managed switch. This means lower up-front costs as well as lower power consumption and a simpler network management scheme are all derived. Rather than dealing with both leaf and spine switches, network administration simply needs to focus on the managed switches at the spine layer.
With no end in sight to the ongoing progression of network capacity, cloud-scale data centers will always have ever-increasing scaling challenges to attend to. The modularized approach described here makes those challenges solvable.
-
June 07, 2017
コミュニティ・プラットフォームにより、データセンター、ネットワークおよびストレージのエコシステムに ARM 64 ビットを簡単に導入可能に
マーベル、シニア・ソフトウェア・プロダクト・ライン・マネージャー、マエン・スレイマン著
Marvell MACCHIATObin community board is first-of-its-kind, high-end ARM 64-bit networking and storage community board
The increasing availability of high-speed internet services is connecting people in novel and often surprising ways, and creating a raft of applications for data centers. Cloud computing, Big Data and the Internet of Things (IoT) are all starting to play a major role within the industry.
These opportunities call for innovative solutions to handle the challenges they present, many of which have not been encountered before in IT. The industry is answering that call through technologies and concepts such as software defined networking (SDN), network function virtualization (NFV) and distributed storage. Making the most of these technologies and unleashing the potential of the new applications requires a collaborative approach. The distributed nature and complexity of the solutions calls for input from many different market participants.
A key way to foster such collaboration is through open-source ecosystems. The rise of Linux has demonstrated the effectiveness of such ecosystems and has helped steer the industry towards adopting open-source solutions. (Examples: AT&T Runs Open Source White Box Switch in its Live Network, SnapRoute and Dell EMC to Help Advance Linux Foundation's OpenSwitch Project, Nokia launches AirFrame Data Center for the Open Platform NFV community)
Communities have come together through Linux to provide additional value for the ecosystem. One example is the Linux Foundation Organization which currently sponsors more than 50 open source projects. Its activities cover various parts of the industry from IoT ( IoTivity , EdgeX Foundry ) to full NFV solutions, such as the Open Platform for NFV (OPNFV). This is something that would have been hard to conceive even a couple of years ago without the wide market acceptance of open-source communities and solutions.
Although there are numerous important open-source software projects for data-center applications, the hardware on which to run them and evaluate solutions has been in short supply. There are many ARM® development boards that have been developed and manufactured, but they primarily focus on simple applications.
All these open source software ecosystems require a development platform that can provide a high-performance central processing unit (CPU), high-speed network connectivity and large memory support. But they also need to be accessible and affordable to ARM developers. Marvell MACCHIATObin® is the first ARM 64-bit community platform for open-source software communities that provides solutions for, among others, SDN, NFV and Distributed Storage.
 A high-performance ARM 64-bit community platform
A high-performance ARM 64-bit community platform The Marvell MACCHIATObin community board is a mini-ITX form-factor ARM 64-bit network and storage oriented community platform. It is based on the Marvell hyperscale SBSA-compliant ARMADA® 8040 system on chip (SoC) that features four high-performance Cortex®-A72 ARM 64-bit CPUs. ARM Cortex-A72 CPU is the latest and most powerful ARM 64-bit CPU available and supports virtualization, an increasingly important aspect for data center applications.
Together with the quad-core platform, the ARMADA 8040 SoC provides two 10G Ethernet interfaces, three SATA 3.0 interfaces and support for up to 16GB of DDR4 memory to handle highly complex applications. This power does not come at the cost of affordability: the Marvell MACCHIATObin community board is priced at $349. As a result, the Marvell MACCHIATObin community board is the first affordable high-performance ARM 64-bit networking and storage community platform of its kind.

SolidRun (https://www.solid-run.com/) started shipping the Marvell MACCHIATObin community board in March 2017, providing an early access of the hardware to open-source communities.
The Marvell MACCHIATObin community board is easy to deploy. It uses the compact mini-ITX form factor, enabling developers to purchase one of the many cases based on the popular standard mini-ITX case to meet their requirements. The ARMADA 8040 SoC itself is SBSA-compliant (http://infocenter.arm.com/help/topic/com.arm.doc.den0029/) to offer unified extensible firmware interface (UEFI) support.
The ARMADA 8040 SoC includes an advanced network packet processor that supports features such as parsing, classification, QoS mapping, shaping and metering. In addition, the SoC provides two security engines that can perform full IPSEC, DTL and other protocol-offload functions at 10G rates. To handle high-performance RAID 5/6 support, the ARMADA 8040 SoC employs high-speed DMA and XOR engines.
For hardware expansion, the Marvell MACCHIATObin community board provides one PCIex4 3.0 slot and a USB3.0 host connector. For non-volatile storage, options include a built-in eMMC device and a micro-SD card connector. Mass storage is available through three SATA 3.0 connectors. For debug, developers can access the board’s processors through a choice of a virtual UART running over the microUSB connector, 20-pin connector for JTAG access or two UART headers. The Marvell MACCHIATObin community board technical specifications can be found here: MACCHIATObin Specification.
Open source software enables advanced applications
The Marvell MACCHIATObin community board comes with rich open source software that includes ARM Trusted Firmware (ATF), U-Boot, UEFI, Linux Kernel, Yocto, OpenWrt, OpenDataPlane (ODP) , Data Plane Development Kit (DPDK), netmap and others; many of the Marvell MACCHIATObin open source software core components are available at: https://github.com/orgs/MarvellEmbeddedProcessors/.
To provide the Marvell MACCHIATObin community board with ready-made support for the open-source platforms used at the edge and data centers for SDN, NFV and similar applications, standard operating systems like Suse Linux Enterprise, CentOS, Ubuntu and others should boot and run seamlessly on the Marvell MACCHIATObin community board.
As the ARMADA 8040 SoC is SBSA compliant and supports UEFI with ACPI, along with Marvell’s upstreaming of Linux kernel support, standard operating systems can be enabled on the Marvell MACCHIATObin community board without the need of special porting.
On top of this core software, a wide variety of ecosystem applications needed for the data center and edge applications can be assembled.
For example, using the ARMADA 8040 SoC high-speed networking and security engine will enable the kernel netdev community to develop and maintain features such as XDP or other kernel network features on ARM 64-bit platforms. The ARMADA 8040 SoC security engine will enable many other Linux kernel open-source communities to implement new offloads.
Thanks to the virtualization support available on the ARM Cortex A72 processors, virtualization technology projects such as KVM and XEN can be enabled on the platform; container technologies like LXC and Docker can also be enabled to maximize data center flexibility and enable a virtual CPE ecosystem where the Marvell MACCHIATObin community board can be used to develop edge applications on a 64-bit ARM platform.
In addition to the mainline Linux kernel, Marvell is upstreaming U-Boot and UEFI, and is set to upstream and open the Marvell MACCHIATObin ODP and DPDK support. This makes the Marvell MACCHIATObin board an ideal community platform for both communities, and will open the door to related communities who have based their ecosystems on ODP or DPDK. These may be user-space network-stack communities such as OpenFastPath and FD.io or virtual switching technologies that can make use of both the ARMADA 8040 SoC virtualization support and networking capabilities such as Open vSwitch (OVS) or Vector Packet Processing (VPP). Similar to ODP and DPDK, Marvell MACCHIATObin netmap support can enable VALE virtual switching technology or security ecosystem such as pfsense.

Thanks to its hardware features and upstreamed software support, the Marvell MACCHIATObin community board is not limited to data center SDN and NFV applications. It is highly suited as a development platform for network and security products and applications such as network routers, security appliances, IoT gateways, industrial computing, home customer-provided equipment (CPE) platforms and wireless backhaul controllers; a new level of scalable and modular solutions can be further achieved when combining the Marvell MACCHIATObin community board with Marvell switches and PHY products.
Summary
The Marvell MACCHIATObin is the first of its kind: a high-performance, cost-effective networking community platform. The board supports a rich software ecosystem and has made available high-performance, high-speed networking ARM 64-bit community platforms at a price that is affordable for the majority of ARM developers, software vendors and other interested companies. It makes ARM 64-bit far more accessible than ever before for developers of solutions for use in data centers, networking and storage.
-
2017年5月23日
Marvell MACCHIATObin コミュニティ・ボードの発送開始
マーベル、シニア・ソフトウェア・プロダクト・ライン・マネージャー、マエン・スレイマン著
First-of-its-kind community platform makes ARM-64bit accessible for data center, networking and storage solutions developers
As network infrastructure continues to transition to Software-Defined Networking (SDN) and Network Functions Virtualization (NFV), the industry is in great need of cost-optimized hardware platforms coupled with robust software support for the development of a variety of networking, security and storage solutions. The answer is finally here!
Now, with the shipping of the Marvell MACCHIATObin™ community board, developers and companies have access to a high-performance, affordable ARM®-based platform with the required technologies such as an ARMv8 64bit CPU, virtualization, high-speed networking and security accelerators, and the added benefit of open source software. SolidRun started shipping the Marvell MACCHIATObin community board in March 2017, providing an early access of the hardware to open-source communities.

Click image to enlarge
The Marvell MACCHIATObin community board is a mini-ITX form-factor ARMv8 64bit network- and storage-oriented community platform. It is based on the Marvell® hyperscale SBSA-compliant ARMADA® 8040 system on chip (SoC) (http://www.marvell.com/embedded-processors/armada-80xx/) that features quad-core high-performance Cortex®-A72 ARM 64bit CPUs
Together with the quad-core Cortex-A72 ARM64bit CPUs, the Marvell MACCHIATObin community board provides two 10G Ethernet interfaces, three SATA 3.0 interfaces and support for up to 16GB of DDR4 memory to handle higher performance data center applications. This power does not come at the cost of affordability: the Marvell MACCHIATObin community board is priced at $349. As a result, it is the first affordable high-performance ARM 64bit networking and storage community platform of its kind.
The Marvell MACCHIATObin community board is easy to deploy. It uses the compact mini-ITX form factor enabling developers and companies to purchase one of the many cases based on the popular standard mini-ITX case to meet their requirements. The ARMADA 8040 SoC itself is SBSA- compliant to offer unified extensible firmware interface (UEFI) support. You can find the full specification at: http://wiki.macchiatobin.net/tiki-index.php?page=About+MACCHIATObin.
To provide the Marvell MACCHIATObin community board with ready-made support for the open-source platforms used in SDN, NFV and similar applications, Marvell is upstreaming MACCHIATObin software support to the Linux kernel, U-Boot and UEFI, and is set to upstream and open the Marvell MACCHIATObin community board for ODP and DPDK support.
In addition to upstreaming the MACCHIATObin software support, Marvell added MACCHIATObin support to the ARMADA 8040 SDK and plans to make the ARMADA 8040 SDK publicly available. Many of the ARMADA 8040 SDK components are available at: https://github.com/orgs/MarvellEmbeddedProcessors/.
For more information about the many innovative features of the Marvell MACCHIATObin community board, please visit: http://wiki.macchiatobin.net. To place an order for the Marvell MACCHIATObin community board, please go to: http://macchiatobin.net/.
-
2017年4月27日
11ac Wave 2と11axでの Wi-Fi 開発での挑戦 2.5GBASE-Tおよび5GBASE-Tへのコスト効率の良いアップグレード方法
ニック・イリヤディス著
The Insatiable Need for Bandwidth: Standards Trying to Keep Up
With the push for more and more Wi-Fi bandwidth, the WLAN industry, its standards committees and the Ethernet switch manufacturers are having a hard time keeping up with the need for more speed. As the industry prepares for upgrading to 802.11ac Wave 2 and the promise of 11ax, the ability of Ethernet over existing copper wiring to meet the increased transfer speeds is being challenged. And what really can’t keep up are the budgets that would be needed to physically rewire the millions of miles of cabling in the world today.
The Latest on the Latest Wireless Networking Standards: IEEE 802.11ac Wave 2 and 802.11ax
The latest 802.11ac IEEE standard is now in Wave 2. According to Webopedia’s definition: the 802.11ac -2013 update, or 802.11ac Wave 2, is an addendum to the original 802.11ac wireless specification that utilizes Multi-User, Multiple-Input, Multiple-Output (MU-MIMO) technology and other advancements to help increase theoretical maximum wireless speeds from 3.47 gigabits-per-second (Gbps), in the original spec, to 6.93 Gbps in 802.11ac Wave 2. The original 802.11ac spec itself served as a performance boost over the 802.11n specification that preceded it, increasing wireless speeds by up to 3x. As with the initial specification, 802.11ac Wave 2 also provides backward compatibility with previous 802.11 specs, including 802.11n.
IEEE has also noted that in the past two decades, the IEEE 802.11 wireless local area networks (WLANs) have also experienced tremendous growth with the proliferation of IEEE 802.11 devices, as a major Internet access for mobile computing. Therefore, the IEEE 802.11ax specification is under development as well. Giving equal time to Wikipedia, its definition of 802.11ax is: a type of WLAN designed to improve overall spectral efficiency in dense deployment scenarios, with a predicted top speed of around 10 Gbps. It works in 2.4GHz or 5GHz and in addition to MIMO and MU-MIMO, it introduces Orthogonal Frequency-Division Multiple Access (OFDMA) technique to improve spectral efficiency and also higher order 1024 Quadrature Amplitude Modulation (QAM) modulation support for better throughputs. Though the nominal data rate is just 37 percent higher compared to 802.11ac, the new amendment will allow a 4X increase of user throughput. This new specification is due to be publicly released in 2019.
Faster “Cats” Cat 5, 5e, 6, 6e and on
And yes, even cabling is moving up to keep up. You’ve got Cat 5, 5e, 6, 6e and 7 (search: Differences between CAT5, CAT5e, CAT6 and CAT6e Cables for specifics), but suffice it to say, each iteration is capable of moving more data faster, starting with the ubiquitous Cat 5 at 100Mbps at 100MHz over 100 meters of cabling to Cat 6e reaching 10,000 Mbps at 500MHz over 100 meters. Cat 7 can operate at 600MHz over 100 meters, with more “Cats” on the way. All of this of course, is to keep up with streaming, communications, mega data or anything else being thrown at the network.
How to Keep Up Cost-Effectively with 2.5BASE-T and 5BASE-T
What this all boils down to is this: no matter how fast the network standards or cables get, the migration to new technologies will always be balanced with the cost of attaining those speeds and technologies in the physical realm. In other words, balancing the physical labor costs associated to upgrade all those millions of miles of cabling in buildings throughout the world, as well as the switches or other access points. The labor costs alone, are a reason why companies often seek out to stay in the wiring closet as long as possible, where the physical layer (PHY) devices, such access and switches, remain easier and more cost effective to switch out, than replacing existing cabling.
This is where Marvell steps in with a whole solution. Marvell’s products, including the Avastar wireless products, Alaska PHYs and Prestera switches, provide an optimized solution that will help support up to 2.5 and 5.0 Gbps speeds, using existing cabling. For example, the Marvell Avastar 88W8997 wireless processor was the industry's first 28nm, 11ac (wave-2), 2x2 MU-MIMO combo with full support for Bluetooth 4.2, and future BT5.0. To address switching, Marvell created the Marvell® Prestera® DX family of packet processors, which enables secure, high-density and intelligent 10GbE/2.5GbE/1GbE switching solutions at the access/edge and aggregation layers of Campus, Industrial, Small Medium Business (SMB) and Service Provider networks. And finally, the Marvell Alaska family of Ethernet transceivers are PHY devices which feature the industry's lowest power, highest performance and smallest form factor.
These transceivers help optimize form factors, as well as multiple port and cable options, with efficient power consumption and simple plug-and-play functionality to offer the most advanced and complete PHY products to the broadband market to support 2.5G and 5G data rate over Cat5e and Cat6 cables.
You mean, I don’t have to leave the wiring closet?
The longer changes can be made at the wiring closet vs. the electricians and cabling needed to rewire, the better companies can balance faster throughput at lower cost. The Marvell Avastar, Prestera and Alaska product families are ways to help address the upgrade to 2.5G- and 5GBASE-T over existing copper wire to keep up with that insatiable demand for throughput, without taking you out of the wiring closet. See you inside!
# # #
-
2017年4月27日
高いデータ帯域需要を維持するための上位 8 つのデータセンターの傾向
VP of Portfolio Technology、Nick Ilyadis 著
IoT devices, online video streaming, increased throughput for servers and storage solutions – all have contributed to the massive explosion of data circulating through data centers and the increasing need for greater bandwidth. IT teams have been chartered with finding the solutions to support higher bandwidth to attain faster data speeds, yet must do it in the most cost-efficient way - a formidable task indeed. Marvell recently shared with eWeek about what it sees as the top trends in data centers as they try to keep up with the unprecedented demand for higher and higher bandwidth. Below are the top eight data center trends Marvell has identified as IT teams develop the blueprint for achieving high bandwidth, cost-effective solutions to keep up with explosive data growth.

1.) Higher Adoption of 25GbE
To support this increased need for high bandwidth, companies are evaluating whether to adopt 40GbE to the server as an upgrade from 10GbE. 25GbE provides more cost effective throughput than 40GbE since 40GbE requires more power and costlier cables. Therefore, 25GbE is becoming acknowledged as an optimal next-generation Ethernet speed for connecting servers as data centers seek to balance cost/performance tradeoffs.
2.) The Ability to Bundle and Unbundle Channels
Historically, data centers have upgraded to higher link speeds by aggregating multiple single-lane 10GbE network physical layers. Today, 100Gbps can be achieved by bundling four 25Gbps links together or alternatively, 100GbE can also be unbundled into four independent 25GbE channels. The ability to bundle and unbundle 100GbE gives IT teams wider flexibility in moving data across their network and in adapting to changing customer needs.
3.) Big Data Analytics
Increased data means increased traffic. Real-time analytics allow organizations to monitor and make adjustments as needed to effectively allocate precious network bandwidth and resources. Leveraging analytics has become a key tool for data center operators to maximize their investment.

4.) Growing Demand for Higher-Density Switches
Advances in semiconductor processes to 28nm and 16nm have allowed network switches to become smaller and smaller. In the past, a 48-port switch required two chips with advanced port configurations. But today, the same result can be achieved on a single chip, which not only keeps costs down, but improves power efficiency.
5.) Power Efficiency Needed to Keep Costs Down
Energy costs are often among the highest costs incurred by data centers. Ethernet solutions designed with greater power efficiency help data centers transition to the higher GbE rates needed to keep up with the higher bandwidth demands, while keeping energy costs in check.

6.) More Outsourcing of IT to the Cloud
IT organizations are not only adopting 25GbE to address increasing bandwidth demands, they are also turning to the cloud. By outsourcing IT to the cloud, organizations are able to secure more space on their network, while maintaining bandwidth speeds.
7.) Using NVM Express-based Storage to Maximize Performance
NVM Express® (NVMe™) is a scalable host controller interface designed to address the needs of enterprise, data center and client systems that utilize PCI-e based solid-state drives (SSDs.) By using the NVMe protocol, data centers can exploit the full performance of SSDs, creating new compute models that no longer have the limitations of legacy rotational media. SSD performance can be maximized, while server clusters can be enabled to pool storage and share data access throughout the network.
 8.) Transition from Servers to Network Storage With the growing amount of data transferred across networks, more data centers are deploying storage on networks vs. servers. Ethernet technologies are being leveraged to attach storage to the network instead of legacy storage interconnects as the data center transitions from a traditional server model to networked storage.
8.) Transition from Servers to Network Storage With the growing amount of data transferred across networks, more data centers are deploying storage on networks vs. servers. Ethernet technologies are being leveraged to attach storage to the network instead of legacy storage interconnects as the data center transitions from a traditional server model to networked storage.As shown above, IT teams are using a variety of technologies and methods to keep up with the explosive increase in data and higher needs for data center bandwidth. What methods are you employing to keep pace with the ever-increasing demands on the data center, and how do you try to keep energy usage and costs down?
# # #
-
March 17, 2017
Three Days, Two Speaking Sessions and One New Product Line: Marvell Sets the (IEEE 802.1BR) Standard for Data Center Solutions at the 2017 OCP U.S. Summit
By Michael Zimmerman, Vice President and General Manager, CSIBU, Marvell
At last week’s 2017 OCP U.S. Summit, it was impossible to miss the buzz and activity happening at Marvell’s booth. Taking our mantra #MarvellOnTheMove to heart, the team worked tirelessly throughout the week to present and demo Marvell’s vision for the future of the data center, which came to fruition with the launch of our newest Prestera® PX Passive Intelligent Port Extender (PIPE) family.
But we’re getting ahead of ourselves…
 Marvell kicked off OCP with two speaking sessions from its leading technologists. Yaniv Kopelman, Networking CTO of the Networking Group, presented "Extending the Lifecycle of 3.2T Switches,” a discussion on the concept of port extender technology and how to apply it to future data center architecture. Michael Zimmerman, vice president and general manager of the Networking Group, then spoke on "Modular Networking" and teased Marvell's first modular solution based on port extender technology.
Marvell kicked off OCP with two speaking sessions from its leading technologists. Yaniv Kopelman, Networking CTO of the Networking Group, presented "Extending the Lifecycle of 3.2T Switches,” a discussion on the concept of port extender technology and how to apply it to future data center architecture. Michael Zimmerman, vice president and general manager of the Networking Group, then spoke on "Modular Networking" and teased Marvell's first modular solution based on port extender technology. Throughout the show, customers, media and attendees visited Marvell’s booth to see our breakthrough innovations that are leading the disaggregation of the cloud network infrastructure industry. These products included:
Marvell's Prestera PX PIPE family purpose-built to reduce power consumption, complexity and cost in the data center
Marvell’s 88SS1092 NVMe SSD controller designed to help boost next-generation storage and data center systems
Marvell’s Prestera 98CX84xx switch family designed to help data centers break the 1W per 25G port barrier for 25G Top-of-Rack (ToR) applications
Marvell’s ARMADA® 64-bit ARM®-based modular SoCs developed to improve the flexibility, performance and efficiency of servers and network appliances in the data center
Marvell’s Alaska® C 100G/50G/25G Ethernet transceivers which enable low-power, high-performance and small form factor solutions
We’re especially excited to introduce our PIPE solution on the heels of OCP because of the dramatic impact we anticipate it will have on the data center…
Until now, data centers with 10GbE and 25GbE port speeds have been challenged with achieving lower operating expense (OPEX) and capital expenditure (CAPEX) costs as their bandwidth needs increase. As the industry’s first purpose-built port extender supporting the IEEE 802.1BR standard, Marvell’s PIPE solution is a revolutionary approach that makes it possible to deploy ToR switches at half the power and cost of a traditional Ethernet switch.
Marvell’s PIPE solution enables data centers to be architected with a very simple, low-cost, low-power port extender in place of a traditional ToR switch, pushing the heavy switching functionality upstream. As the industry today transitions from 10GbE to 25GbE and from 40GbE to 100GbE port speeds, data centers are also in need of a modular building block to bridge the variety of current and next-generation port speeds. Marvell’s PIPE family provides a flexible and scalable solution to simplify and accelerate such transitions, offering multiple configuration options of Ethernet connectivity for a range of port speeds and port densities.

Amidst all of the announcements, speaking sessions and demos, our very own George Hervey, principal architect, also sat down with Semiconductor Engineering’s Ed Sperling for a Tech Talk. In the white board session, George discussed the power efficiency of networking in the enterprise and how costs can be saved by rightsizing Ethernet equipment.
The 2017 OCP U.S. Summit was filled with activity for Marvell, and we can’t wait to see how our customers benefit from our suite of data center solutions. In the meantime, we’re here to help with all of your data center needs, questions and concerns as we watch the industry evolve.
What were some of your OCP highlights? Did you get a chance to stop by the Marvell booth at the show? Tweet us at @marvellsemi to let us know, and check out all of the activity from last week. We want to hear from you!
-
March 13, 2017
ネットワークスイッチの業界を変えるポート・エクステンダー技術
寄稿 ジョージ ハーベイ, マーベルセミコンダクタ社 主任アーキテクト
 Our lives are increasingly dependent on cloud-based computing and storage infrastructure. Whether at home, at work, or on the move with our smartphones and other mobile computing devices, cloud compute and storage resources are omnipresent. It is no surprise therefore that the demands on such infrastructure are growing at an alarming rate, especially as the trends of big data and the internet of things start to make their impact. With an increasing number of applications and users, the annual growth rate is believed to be 30x per annum, and even up to 100x in some cases. Such growth leaves Moore’s law and new chip developments unable to keep up with the needs of the computing and network infrastructure. These factors are making the data and communication network providers invest in multiple parallel computing and storage resources as a way of scaling to meet demands. It is now common for cloud data centers to have hundreds if not thousands of servers that need to be connected together.
Our lives are increasingly dependent on cloud-based computing and storage infrastructure. Whether at home, at work, or on the move with our smartphones and other mobile computing devices, cloud compute and storage resources are omnipresent. It is no surprise therefore that the demands on such infrastructure are growing at an alarming rate, especially as the trends of big data and the internet of things start to make their impact. With an increasing number of applications and users, the annual growth rate is believed to be 30x per annum, and even up to 100x in some cases. Such growth leaves Moore’s law and new chip developments unable to keep up with the needs of the computing and network infrastructure. These factors are making the data and communication network providers invest in multiple parallel computing and storage resources as a way of scaling to meet demands. It is now common for cloud data centers to have hundreds if not thousands of servers that need to be connected together. Interconnecting all of these compute and storage appliances is becoming a real challenge, as more and more switches are required. Within a data center a classic approach to networking is a hierarchical one, with an individual rack using a leaf switch – also termed a top-of-rack or ToR switch – to connect within the rack, a spine switch for a series of racks, and a core switch for the whole center. And, like the servers and storage appliances themselves, these switches all need to be managed. In the recent past there have usually been one or two vendors of data center network switches and the associated management control software, but things are changing fast. Most of the leading cloud service providers, with their significant buying power and technical skills, recognised that they could save substantial cost by designing and building their own network equipment. Many in the data center industry saw this as the first step in disaggregating the network hardware and the management software controlling it. With no shortage of software engineers, the cloud providers took the management software development in-house while outsourcing the hardware design. While that, in part, satisfied the commercial needs of the data center operators, from a technical and operational management perspective nothing has been simplified, leaving a huge number of switches to be managed.
The first breakthrough to simplify network complexity came in 2009 with the introduction of what we know now as a port extender. The concept rests on the belief that there are many nodes in the network that don’t need the extensive management capabilities most switches have. Essentially this introduces a parent/child relationship, with the controlling switch, the parent, being the managed switch and the child, the port extender, being fed from it. This port extender approach was ratified into the networking standard 802.1BR in 2012, and every network switch built today complies with this standard. With less technical complexity within the port extenders, there were perceived benefits that would come from lower per unit cost compared to a full bridge switch, in addition to power savings.
The controlling bridge and port extender approach has certainly helped to drive simplicity into network switch management, but that’s not the end of the story. Look under the lid of a port extender and you’ll find the same switch chip being used as in the parent bridge. We have moved forward, sort of. Without a chip specifically designed as a port extender switch vendors have continued to use their standard chips sets, without realising potential cost and power savings. However, the truly modular approach to network switching has taken a leap forward with the launch of Marvell’s 802.1BR compliant port extender IC termed PIPE – passive intelligent port extender, enabling interoperability with a controlling bridge switch from any of the industry’s leading OEMs. It also offers attractive cost and power consumption benefits, something that took the shine off the initial interest in port extender technology. Seen as the second stage of network disaggregation, this approach effectively leads to decoupling the port connectivity from the processing power in the parent switch, creating a far more modular approach to networking. The parent switch no longer needs to know what type of equipment it is connecting to, so all the logic and processing can be focused on the parent, and the port I/O taken care of in the port extender.
Marvell’s Prestera® PIPE family targets data centers operating at 10GbE and 25GbE speeds that are challenged to achieve lower CAPEX and OPEX costs as the need for bandwidth increases. The Prestera PIPE family will facilitate the deployment of top-of-rack switches at half the cost and power consumption of a traditional Ethernet switch. The PIPE approach also includes a fast fail over and resiliency function, essential for providing continuity and high availability to critical infrastructure.
-
March 08, 2017
NVMe ベースのワークファブリックは、データセンターにおける従来の回転型メディアの限界を克服: NVMe SSD 共有ストレージのスピードとコストの利点は、第2世代に発展しました。
VP of Portfolio Technology、Nick Ilyadis 著
マーベル、88SS1092 第 2 世代 NVM Express SSD コントローラを OCP Summit で初披露
 データセンターでの SSD: NVMe and Where We’ve Been
データセンターでの SSD: NVMe and Where We’ve Been When solid-state drives (SSDs) were first introduced into the data center, the infrastructure mandated they work within the confines of the then current bus technology, such as Serial ATA (SATA) and Serial Attached SCSI (SAS), developed for rotational media. 最速のハードディスクドライブ(HDD)でさえもちろん SSD には及びませんでしたが、最新のパイプラインでもそれがボトルネックになって SSD テクノロジーを最大限に活用できませんでした。 PCI Express(PCIe)は、すでにネットワーキング、グラフィックス、その他のアドインカード用のトランスポートレイヤーとして展開されていた、最適な高帯域幅バステクノロジーを提供していました。 PCIe が次に選択可能なオプションとなりましたが、このインターフェースでさえ古い HDD ベース SCSI または SATA プロトコルに依存していました。 そのため、NVM Express(NVMe)業界ワーキンググループが、PCIe バス用に開発された標準化されたプロトコルおよびコマンドセットを作成するために結成されました。それは、データセンター内で SSD のすべての利点を最大限に活用できる、複数のパスを使用できるようにすることを目的としていました。 この NVMe 仕様は、現在および将来の NVM テクノロジー用に高帯域幅かつ低遅延なストレージを実現するために、ゼロから設計されました。
NVMe インターフェースは最適化されたコマンド発行/完了パスを提供します。 デバイスへの単一 I/O キュー内で 64K までのコマンドをサポートすることで、並行運用をサポートします。 さらに、エンドツーエンドデータ保護(T10 DIF および DIX 標準と互換)、拡張エラーレポート/仮想化などのさまざまなエンタープライズ機能のサポートが追加されています。 要するに NVMeは、 PCIe ベースソリッドステートドライブを利用するエンタープライズ、データセンター、およびクライアントシステムのニーズに対応するために設計された、SSD パフォーマンスを最大化するのに役立つ、スケーラブルなホストコントローラインターフェースです。
SSD Network Fabrics
New NVMe controllers from companies like Marvell allowed the data center to share storage data to further maximize cost and performance efficiencies. SSD ネットワークファブリックを作成して SSD クラスターを形成することで、個々のサーバーのストレージをプールしてデータセンターストレージを最大化できます。 さらに、追加サーバー用に共通エンクロージャを作成することで、データを転送してデータアクセスを共有できます。 これらの新しいコンピュートモデルを導入すれば、データセンターは SSD の高速パフォーマンスを最大限に最適化できるだけでなく、これらの SSD をデータセンターにより経済的に展開できるため、全体的なコストを低減して保守を効率化できます。 個々のサーバーに SSD を追加する代わりに、あまり展開されていない SSD を利用して、割り当てが多いサーバーに再展開して使用することもできます。
これらのネットワークファブリックの機能を示す簡単な例を紹介します。 あるシステムが 7 個のサーバーで構成され、それぞれ PCIe バスに SSD が装着されている場合、各 SSD から SSD クラスターを形成することで、追加ストレージの手段を提供するだけでなく、データアクセスをプールして共有する方法も提供することになります。 たとえば、あるサーバーが 10 パーセントしか利用されず、別のサーバーが過剰に割り当てられている場合、SSD クラスターを導入することで、個々のサーバーに SSD を追加することなく、過剰割り当てのサーバーにストレージを追加できます。 この例でサーバー数が数百になると、コスト、保守、およびパフォーマンス効率が急激に増加します。
マーベルは、最初の NVMe SSD コントローラ導入時に、これらの新しいタイプのコンピュートモデルの準備を支援してくれました。 その製品は最大で 4 つの PCIe 3.0 レーンをサポートしており、ホストシステムのカスタマイズに応じて 4GB/s または 2Gb/s エンドポイントのすべてに最適でした。 NVMe の先進的なコマンド処理を使用して、圧倒的な IOPS パフォーマンスを実現しました。 高速 PCIe 接続を最大限に利用するために、マーベルの革新的な NVMe 設計はハードウェア自動化を大規模に展開することで、PCIe リンクデータフローを円滑化しました。 これにより、従来のホスト制御ボトルネックが軽減され、真のフラッシュパフォーマンスが引き出されました。
Second-Generation NVMe Controllers are Here!
この最初の製品の後に、Marvell 88SS1092 第 2 世代 NVMe SSD コントローラが登場しています。社内の SSD 検証および他社製 OS/プラットフォーム互換性テストに合格している製品です。 このため、Marvell® 88SS1092 は次世代のストレージおよびデータセンターシステムを後押しする製品として、カリフォルニア州サンノゼで 3 月 8 日と 9 日に催される Open Computing Project (OCP) Summit で発表される予定です。
The Marvell 88SS1092 is Marvell's second-generation NVMe SSD controller capable of PCIe 3.0 X 4 end points to provide full 4GB/s interface to the host and help remove performance bottlenecks. While the new controller advances a solid-state storage system to a more fully flash-optimized architecture for greater performance, it also includes Marvell's third-generation error-correcting, low-density parity check (LDPC) technology for the additional reliability enhancement, endurance boost and TLC NAND device support on top of MLC NAND.
NVMe SSD 共有ストレージの速度/コスト上の利点は、信頼性が高いだけでなく、第 2 世代に入っていることです。 ネットワークのパラダイムシフトが起きています。 SSD のパフォーマンスを最大限に活用するためにゼロから設計された NVMe プロトコルを使用することで、新しいコンピュートモデルは従来の回転メディアの制限なしで作成されています。 SSD パフォーマンスを最大化しながら、SSD クラスターと新しいネットワークファブリックによってプールストレージと共有データアクセスを実現します。 ワーキンググループの努力によって今日のデータセンターが現実になり、新しいコントローラとテクノロジーによって SSD テクノロジーのパフォーマンスとコスト効率が最適化されています。
Marvell 88SS1092 Second-Generation NVMe SSD Controller
New process and advanced NAND controller design includes:
-
January 20, 2017
新たなスケーリングのパラダイム: イーサネット・ポート・エクステンダー
By Michael Zimmerman, Vice President and General Manager, CSIBU, Marvell
Over the last three decades, Ethernet has grown to be the unifying communications infrastructure across all industries. More than 3M Ethernet ports are deployed daily across all speeds, from FE to 100GbE. In enterprise and carrier deployments, a combination of pizza boxes — utilizing stackable and high-density chassis-based switches — are used to address the growth in Ethernet. However, over the past several years, the Ethernet landscape has continued to change. With Ethernet deployment and innovation happening fastest in the data center, Ethernet switch architecture built for the data center dominates and forces adoption by the enterprise and carrier markets. This new paradigm shift has made architecture decisions in the data center critical and influential across all Ethernet markets. However, the data center deployment model is different.
How Data Centers are Different
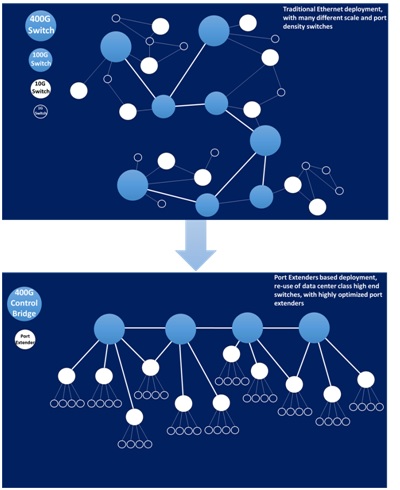 Ethernet port deployment in data centers tends to be uniform, the same Ethernet port speed whether 10GbE, 25GbE or 50GbE is deployed to every server through a top of rack (ToR) switch, and then aggregated in multiple CLOS layers. The ultimate goal is to pack as many Ethernet ports at the highest commercially available speed onto the Ethernet switch, and make it the most economical and power efficient. The end point connected to the ToR switch is the server NIC which is typically the highest available speed in the market (currently 10/25GbE moving to 25/50GbE). Today, 128 ports of 25GbE switches are in deployment, going to 64x 100GbE and beyond in the next few years. But while data centers are moving to higher port density and higher port speeds, and homogenous deployment, there is still a substantial market for lower speeds such as 10GbE that continues to be deployed and must be served economically. The innovation in data centers drives higher density and higher port speeds but many segments of the market still need a solution with lower port speeds with different densities. How can this problem be solved?
Ethernet port deployment in data centers tends to be uniform, the same Ethernet port speed whether 10GbE, 25GbE or 50GbE is deployed to every server through a top of rack (ToR) switch, and then aggregated in multiple CLOS layers. The ultimate goal is to pack as many Ethernet ports at the highest commercially available speed onto the Ethernet switch, and make it the most economical and power efficient. The end point connected to the ToR switch is the server NIC which is typically the highest available speed in the market (currently 10/25GbE moving to 25/50GbE). Today, 128 ports of 25GbE switches are in deployment, going to 64x 100GbE and beyond in the next few years. But while data centers are moving to higher port density and higher port speeds, and homogenous deployment, there is still a substantial market for lower speeds such as 10GbE that continues to be deployed and must be served economically. The innovation in data centers drives higher density and higher port speeds but many segments of the market still need a solution with lower port speeds with different densities. How can this problem be solved? Bridging the Gap
Fortunately, the technology to bridge lower speed ports to higher density switches has existed for several years. The IEEE standards codified the 802.1br port extender standard as the protocol needed to allow a fan-out of ports from an originating higher speed port. In essence, one high end, high port density switch can fan out hundreds or even thousands of lower speed ports. The high density switch is the control bridge, while the devices which fan out the lower speed ports are the port extenders.
Why Use Port Extenders
In addition to re-packaging the data center switch as a control bridge, there are several unique advantages for using port extenders:
Port extenders are only a fraction of the cost, power and board space of any other solution aimed for serving Ethernet ports.
Port extenders have very little or no software. This simplified operational deployment results in the number of managed entities limited to only the high end control bridges.
Port extenders communicate with any high-end switch, via standard protocol 802.1br. Additional options such as Marvell DSA, or programmable headers are possible.)
Port extenders work well with any transition service: 100GbE to 10GbE ports, 400GbE to 25GbE ports, etc.
Port extenders can operate in any downstream speed: 1GbE, 2.5GbE, 10GbE, 25GbE, etc.
Port extenders can be oversubscribed or non-oversubscribed, which means the ratio of upstream bandwidth to downstream bandwidth can be programmable from 1:1 to 1:4 (depending on the application). This by itself can lower cost and power by a factor of 4x.
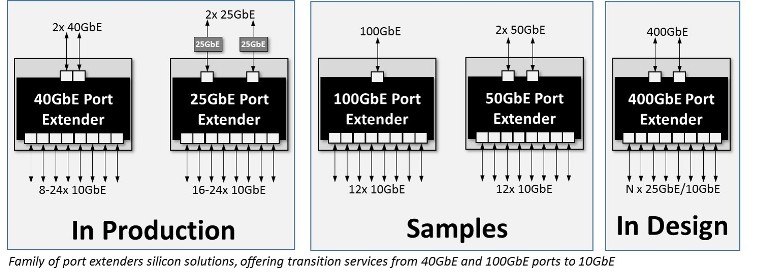
Marvell Port Extenders
Marvell has launched multiple purpose-built port extender products, which allow fan-out of 1GbE and 10GbE ports of 40GbE and 100GbE higher speed ports. Along with the silicon solution, software reference code is available and can be easily integrated to a control bridge. Marvell conducted interoperability tests with a variety of control bridge switches, including the leading switches in the market. The benchmarked design offers 2x cost reduction and 2x power savings. SDK, data sheet and design package are available. Marvell IEEE802.1br port extenders are shipping to the market now. Contact your sales representatives for more information.
-
January 09, 2017
イーサネットにまつわるダーウィン説: 適者生存 (高速な製品が生き残る)
By Michael Zimmerman, Vice President and General Manager, CSIBU, Marvell
The most notable metric of Ethernet technology is the raw speed of communications. Ethernet has taken off in a meaningful way with 10BASE-T, which was used ubiquitously across many segments. With the introduction of 100BASE-T, the massive 10BASE-T installed base was replaced, showing a clear Darwinism effect of the fittest (fastest) displacing the prior and older generation. However, when 1000BASE-T (GbE – Gigabit Ethernet) was introduced, contrary to industry experts’ predictions, it did not fully displace 100BASE-T, and the two speeds have co-existed for a long time (more than 10 years). In fact, 100BASE-T is still being deployed in many applications. The introduction — and slow ramp — of 10GBASE-T has not impacted the growth of GbE, and it is only recently that GbE ports began consistently growing year over year. This trend signaled a new evolution paradigm of Ethernet: the new doesn’t replace the old, and the co-existence of multi variants is the general rule. The introduction of 40GbE and 25GbE augmented the wide diversity of Ethernet speeds, and although 25GbE was rumored to displace 40GbE, it is expected that 40GbE ports will still be deployed over the next 10 years1.
 Hence, a new market reality evolved: there is less of a cannibalizing effect (i.e. newer speed cannibalizing the old), and more co-existence of multiple variants. This new diversity will require a set of solutions which allow effective support for multiple speed interconnect. Two critical capabilities will be needed:
Hence, a new market reality evolved: there is less of a cannibalizing effect (i.e. newer speed cannibalizing the old), and more co-existence of multiple variants. This new diversity will require a set of solutions which allow effective support for multiple speed interconnect. Two critical capabilities will be needed:経済的に少数のポートへとスケールダウンする能力2
Support of multiple Ethernet speeds
Marvell launched a new set of Ethernet interconnect solutions that meet this evolution pattern. The first products in the family are the Prestera® 98DX83xx 320G interconnect switch, and the Alaska® 88X5113 25G/40G Gearbox PHY. The 98DX83xx switch fans-out up to 32-ports of 10GbE or 8-ports of 40GbE, in economical 24x20mm package, with power of less than 0.5Watt/10G port.
 The 88X5113 Gearbox converts a single port of 40GbE to 25GbE. The combination of the two devices creates unique connectivity configurations for a myriad of Ethernet speeds, and most importantly enables scale down to a few ports. While data center- scale 25GbE switches have been widely available for 64-ports, 128-ports (and beyond), a new underserved market segment evolved for a lower port count of 25GbE and 40GbE. Marvell has addressed this space with the new interconnect solution, allowing customers to configure any number of ports to different speeds, while keeping the power envelope to sub-20Watt, and a fraction of the hardware/thermal footprint of comparable data center solutions. The optimal solution to serve low port count connectivity of 10GbE, 25GbE, and 40GbE is now well addressed by Marvell. Samples and development boards with SDK are ready, with the option of a complete package of application software.
The 88X5113 Gearbox converts a single port of 40GbE to 25GbE. The combination of the two devices creates unique connectivity configurations for a myriad of Ethernet speeds, and most importantly enables scale down to a few ports. While data center- scale 25GbE switches have been widely available for 64-ports, 128-ports (and beyond), a new underserved market segment evolved for a lower port count of 25GbE and 40GbE. Marvell has addressed this space with the new interconnect solution, allowing customers to configure any number of ports to different speeds, while keeping the power envelope to sub-20Watt, and a fraction of the hardware/thermal footprint of comparable data center solutions. The optimal solution to serve low port count connectivity of 10GbE, 25GbE, and 40GbE is now well addressed by Marvell. Samples and development boards with SDK are ready, with the option of a complete package of application software.
In the mega data center market, there is cannibalization effect of former Ethernet speeds, and mass migration to higher speeds. However, in the broader market which includes private data centers, enterprise, carriers, multiple Ethernet speeds co-exist in many use cases.
Ethernet switches with high port density of 10GbE and 25GbE are generally available. However, these solutions do not scale down well to sub-24 ports, where there is pent-up demand for devices as proposed here by Marvell.
-
October 13, 2016
Marvell Unveils Industry’s First 25G PHY Transceiver Fully Compliant to IEEE 802.3by 25GbE Specification
By Venu Balasubramonian, Marketing Director, Connectivity, Storage and Infrastructure Business Unit, Marvell
Alaska C 88X5123 enables adoption of 25G Ethernet in datacenters and enterprise networks
 Server room in data center.
Server room in data center. Growing demand for networking bandwidth is one of the biggest pain points facing datacenters today. To keep up with increased bandwidth needs, datacenters are transitioning from 10G to 25G Ethernet (GbE). To enable this, IEEE developed the 802.3by specifications defining Ethernet operation at 25Gbps, which was ratified recently. We are excited to introduce the high performance Marvell Alaska C 88X5123 Ethernet transceiver, the industry’s first PHY transceiver fully compliant to the new IEEE 25GbE specification.
Availability of standards-compliant equipment is critical for the growth and widespread adoption of 25GbE. By delivering the industry’s first PHY device fully compliant to the IEEE 802.3by 25GbE specification, we are enabling our customers to address the 25GbE market by developing products and applications that meet this newly defined specification.
In addition to supporting the IEEE 802.3by 25GbE specification, our 88X5123 is also fully compliant to the IEEE 802.3bj 100GbE specification and the 25/50G Ethernet Consortium specification. The device is packaged in a small 17mm x 17mm package, and supports 8 ports of 25GbE, four ports of 50GbE or two ports of 100GbE operation. The device also supports gearboxing functionality to enable high density 40G Ethernet solutions, on switch ASICs with native 25G I/Os.
With support for long reach (LR) SerDes, and integrated forward error correction (FEC) capability, the 88X5123 supports a variety of media types including single mode and multi-mode optical modules, passive and active copper direct attach cables, and copper backplanes. The device offers a fully symmetric architecture with LR SerDes and FEC capability on host and line interfaces, giving customers the flexibility for their system designs.
For more information on Marvell’s Alaska C 88X5123 Ethernet transceiver, please visit: http://www.marvell.com/transceivers/alaska-c-gbe/
-
May 01, 2016
マーベル、Linux Foundation プロジェクトでエンタープライズグレードのネットワークオペレーティングシステムをサポート
By Yaniv Kopelman, Networking and Connectivity CTO, Marvell
As organizations continue to invest in data centers to host a variety of applications, more demands are placed on the network infrastructure. The deployment of white boxes is an approach organizations can take to meet their networking needs. White box switches are a “blank” standard hardware that relies on a network operating system, commonly Linux-based. White box switches coupled with Open Network Operating Systems enable organizations to customize the networking features that support their objectives and streamline operations to fit their business.
Marvell is committed to powering the key technologies in the data center and the enterprise network, which is why we are proud to be a contributor to the OpenSwitch Project by The Linux Foundation. Built to run on Linux and open hardware, OpenSwitch is a full-featured network operating system (NOS) aimed at enabling the transition to disaggregated networks. OpenSwitch allows for freedom of innovation while maintaining stability and limiting vulnerability, and has a reliable architecture focused on modularity and availability. The open source OpenSwitch NOS allows developers to build networks that prioritize business-critical workloads and functions, and removes the burdens of interoperability issues and complex licensing structures that are inherent in proprietary systems.
As a provider of switches and PHYs for data center and campus networking markets, Marvell believes that the open source OpenSwitch NOS will help the deployment of white boxes in the data center and campus networks. Developers will be able to build networks that prioritize business-critical workloads and functions, removing the burdens of interoperability issues and complex licensing structures that are inherent in proprietary systems.
Our first contribution is to port the Marvell Switch Software Development Kit (CPSS) to support OpenSwitch. This contribution to an industry standard NOS will enable Marvell devices to be widely used across different markets and boxes. To learn more, please visit: http://www.openswitch.net/, or read the full press release.


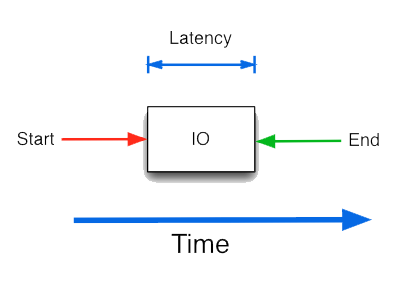

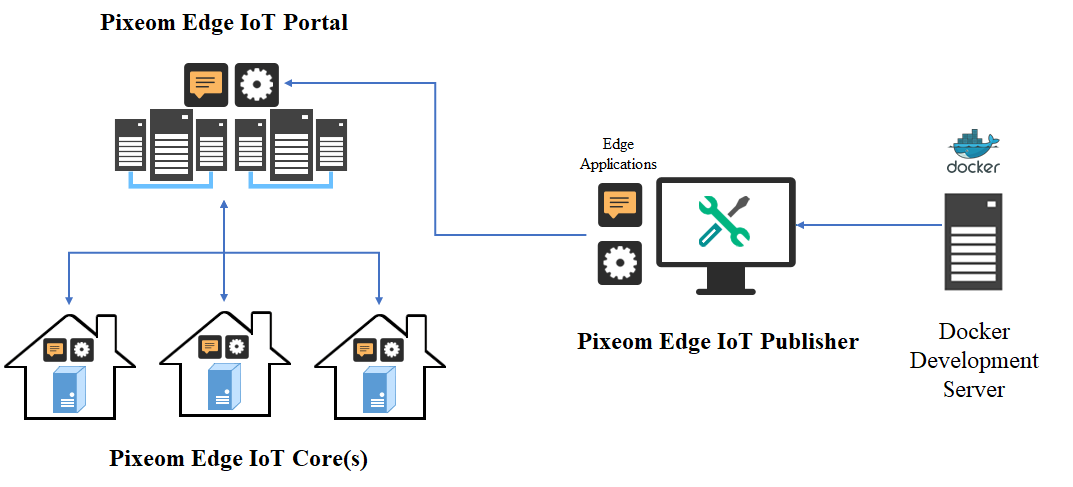
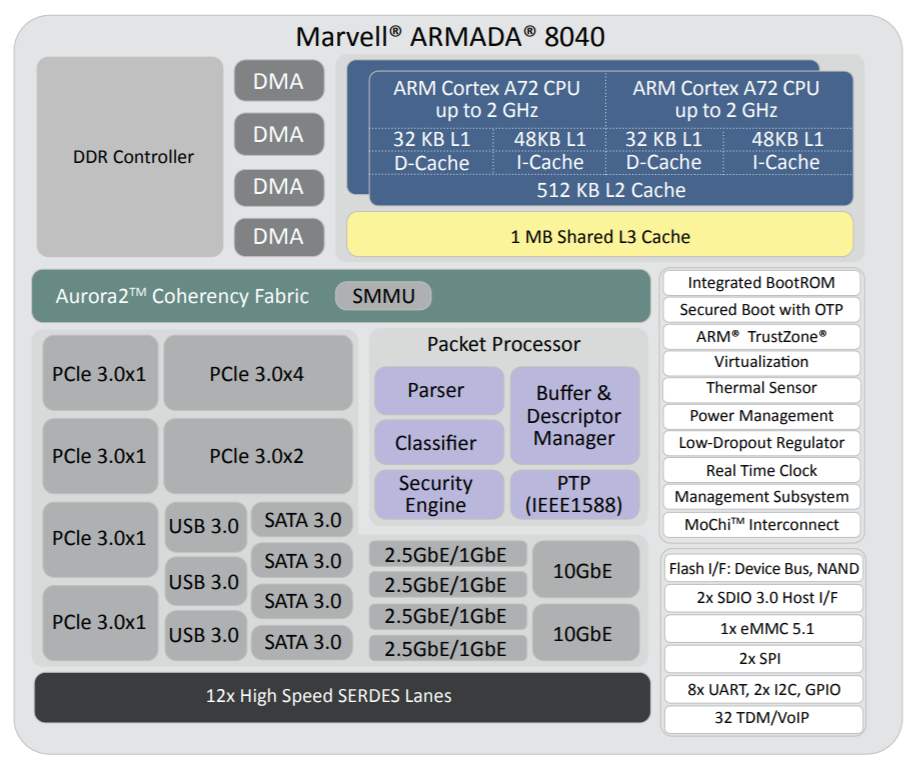

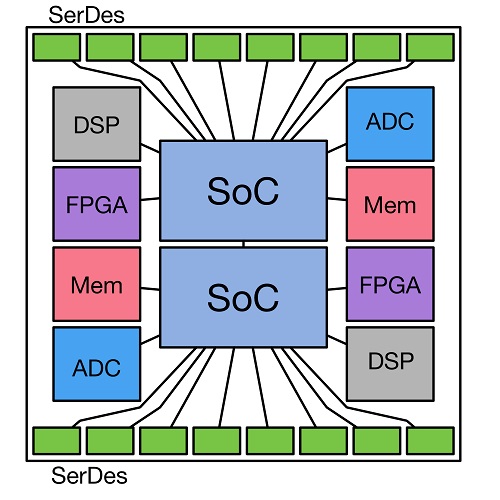
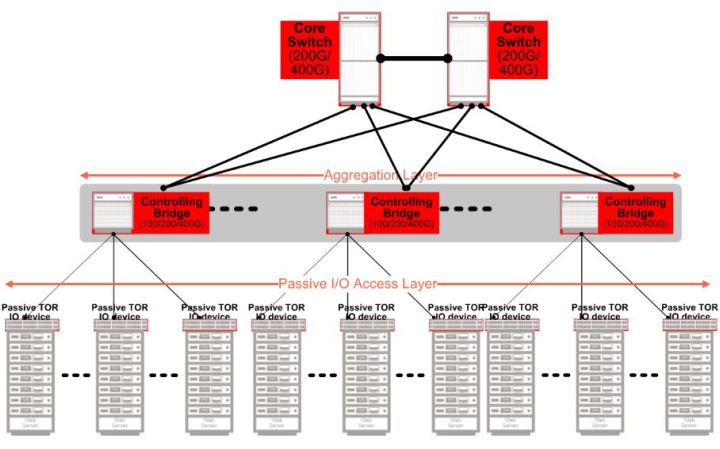










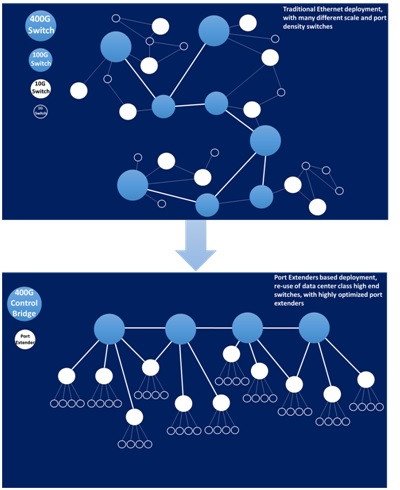
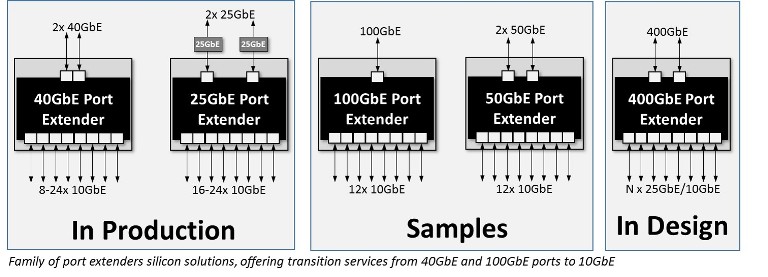
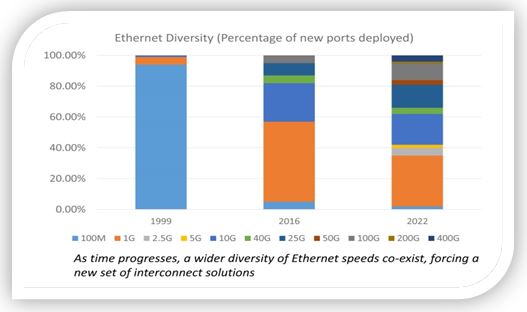

最新の記事
- HashiCorp and Marvell: Teaming Up for Multi-Cloud Security Management
- Cryptomathic and Marvell: Enhancing Crypto Agility for the Cloud
- The Big, Hidden Problem with Encryption and How to Solve It
- Self-Destructing Encryption Keys and Static and Dynamic Entropy in One Chip
- Dual Use IP: Shortening Government Development Cycles from Two Years to Six Months
